A data centre has two halves that don’t talk to each other. Grey space — power distribution, cooling, physical plant — runs on one set of protocols, tools, and teams. White space — compute, workloads, GPUs — runs on another. Redfish can tell you a server’s inlet temperature. BACnet can tell you a CRAC unit’s setpoint. But neither can tell the cooling system that a training job is about to spike thermal load by 40kW in 60 seconds, or tell the workload scheduler that cooling capacity in Zone A is constrained for the next 20 minutes.
Existing protocols are device-level. They let you talk to equipment. What’s missing is a coordination protocol — one that lets grey space and white space communicate constraints, capacity, and intent to each other bidirectionally and in real time. A protocol that sits above Redfish, BACnet, SNMP, and the rest, not replacing them but unifying what they report into a shared operational picture.
This protocol doesn’t exist yet. It would need to come from a consortium — OCP, IEC, or a new working group — not from a single vendor. What I’ve been building is a working prototype of what such a protocol could look like. I’m calling it ARMP (Adaptive Resource Management Protocol) as a placeholder. The implementation details are less important than the argument: this layer is missing, and until it exists, grey space and white space will continue operating as two systems that happen to share a building.
The hardest part of building the prototype wasn’t the AI. It was getting the equipment to talk to each other.
A typical AI-ready data centre floor has CRAC units on BACnet, PDUs on SNMP, server BMCs on IPMI or Redfish, building management on Modbus, IoT sensors on MQTT, industrial automation on OPC-UA. Six standards bodies, six eras, six definitions of “infrastructure management.”
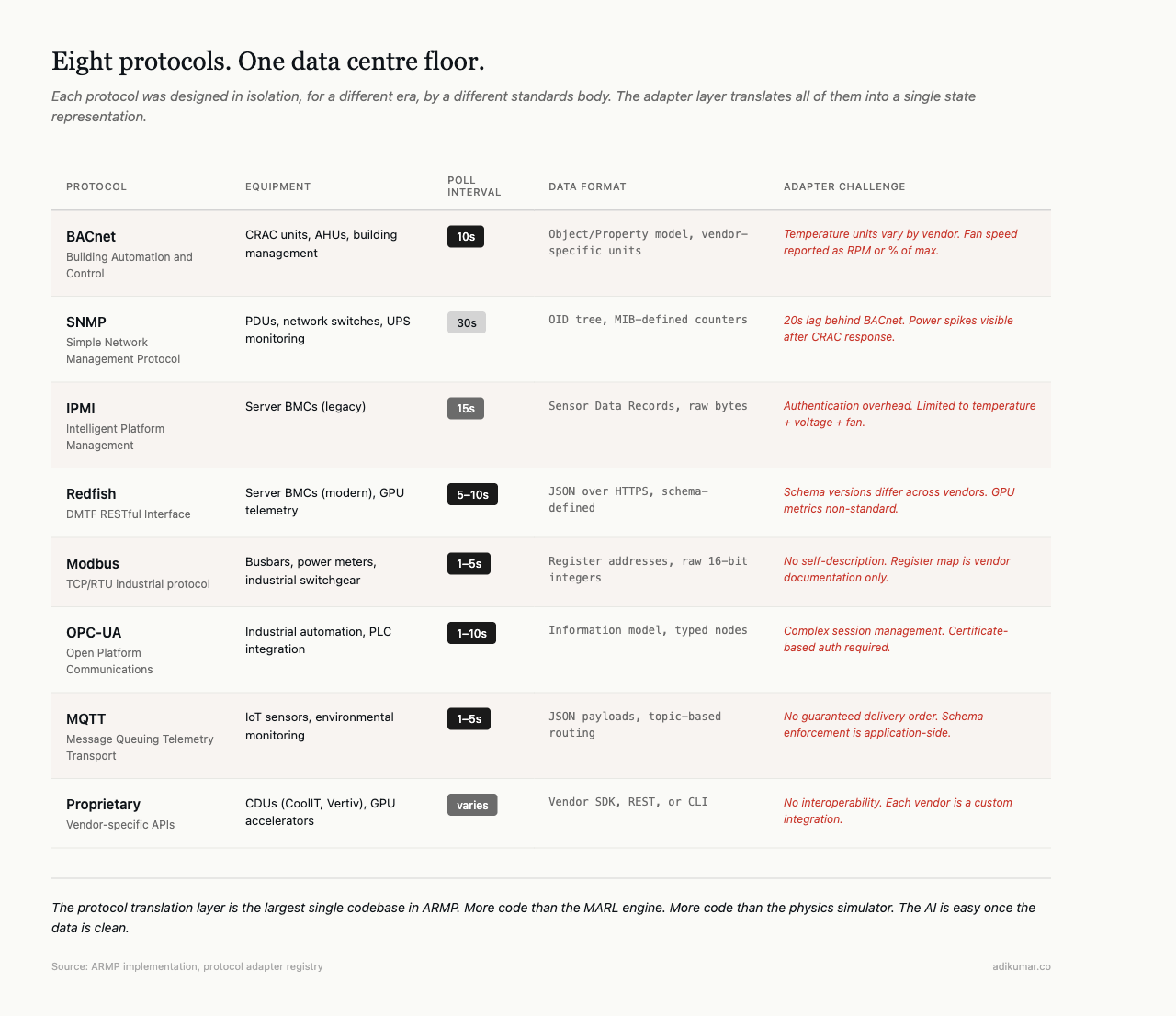
The first component wasn’t a reinforcement learning engine or a digital twin. It was eight protocol adapters. Modbus TCP/RTU for industrial equipment. SNMP for network-managed devices. BACnet for building systems. Redfish for server management. OPC-UA for industrial automation. IPMI for BMC communication. MQTT for IoT sensors. Plus a registry to discover and bind them at runtime.
Each adapter translates vendor-specific telemetry into a common state representation. Temperature from a BACnet CRAC unit needs to be comparable with temperature from an SNMP PDU sensor. Power draw from a Modbus busbar needs to reconcile with power draw from a Redfish server. This translation layer is what a coordination protocol would standardise — today, every integrator builds their own.
The data problem beneath the AI problem
Trade press covers AI in data centres as though the intelligence is the hard part. Train a model, deploy an agent, watch the PUE drop. The assumption is that clean, comparable, real-time data is already available.
In our system, a CRAC agent observes 17 dimensions of state every 10-60 seconds: supply air temperature, return air temperature, fan speed, compressor state, coolant flow rate, setpoint, and several derived metrics. That data comes from a BACnet controller that reports temperatures in different units depending on the vendor, fan speeds as either RPM or percentage of maximum, and compressor state as either binary or multi-state. The adapter normalises all of this into a consistent observation vector before the RL agent sees any of it.
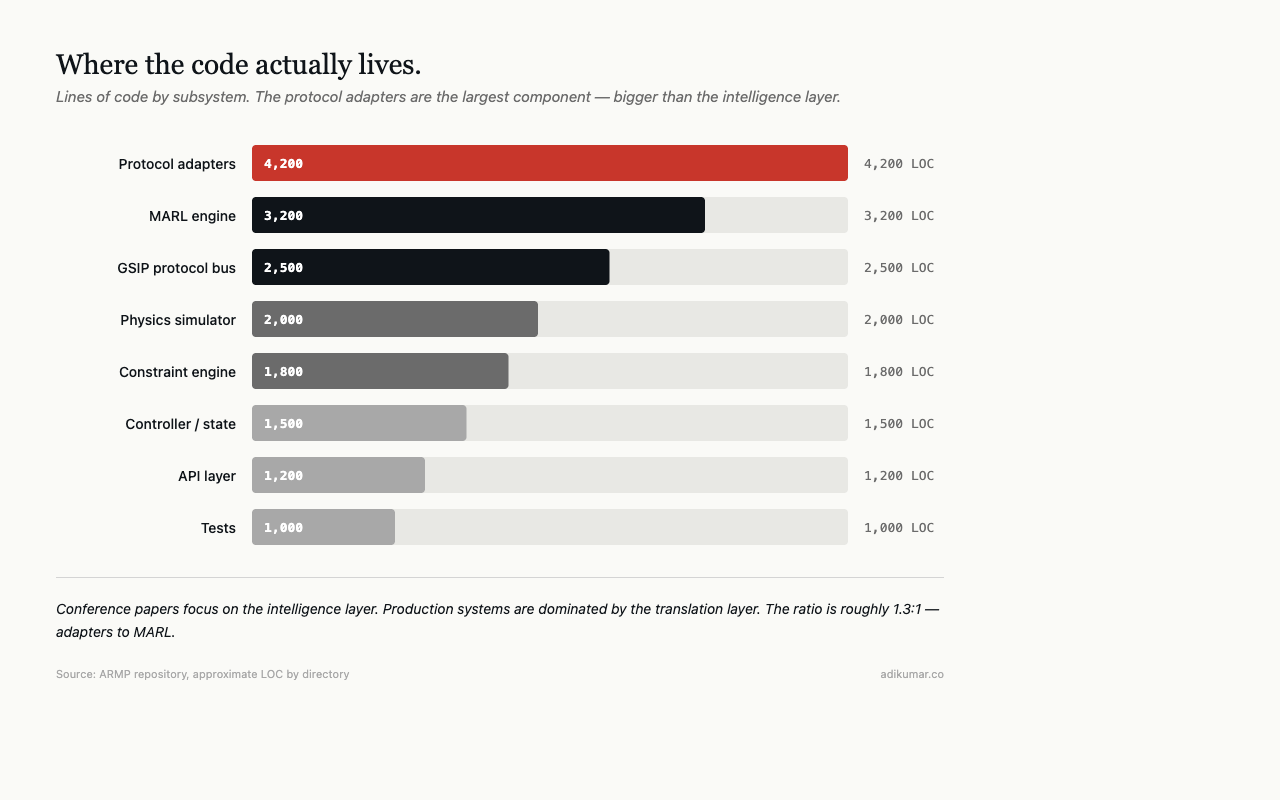
Scale that across 32 agents and five equipment types. The protocol translation layer becomes the largest single codebase in the system — larger than the MARL engine, the physics simulator, or the API layer.
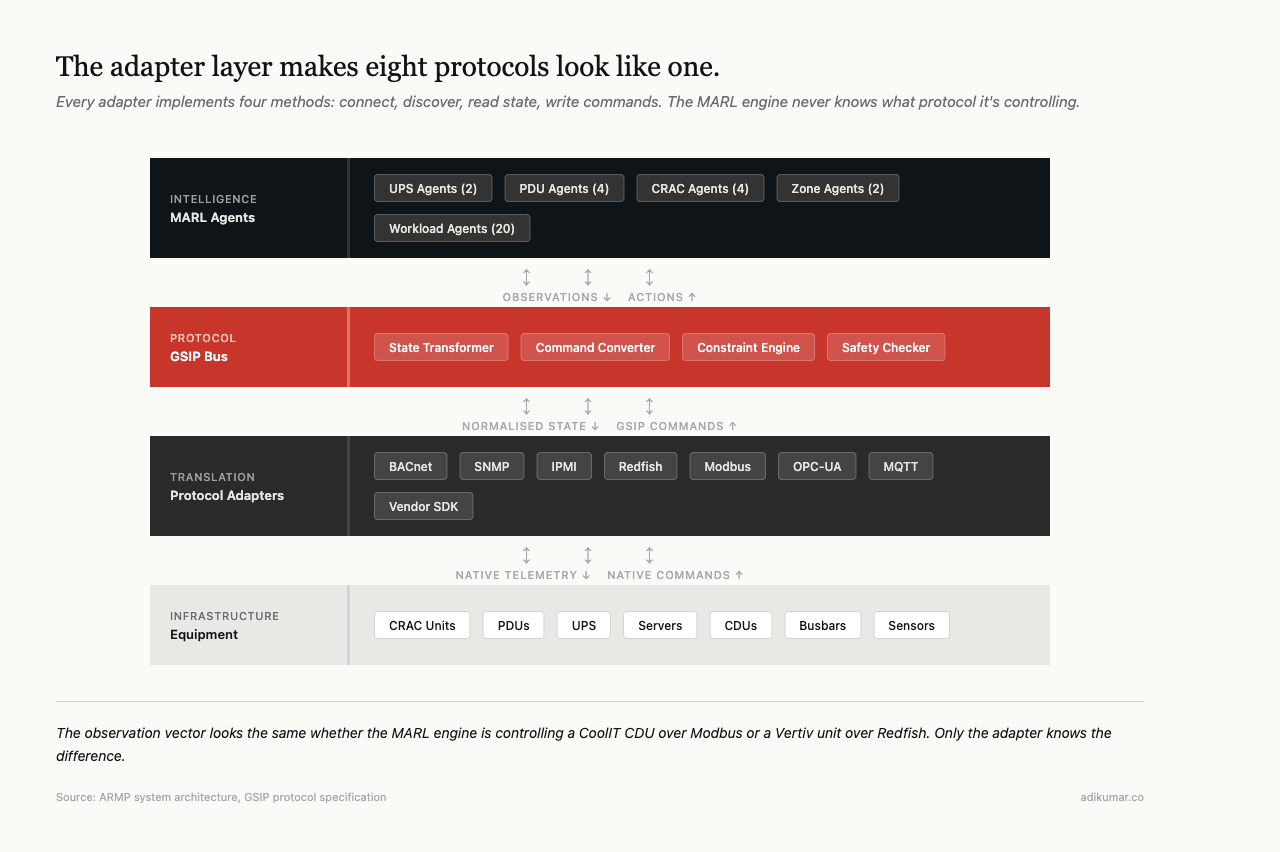
Unified southbound interface
Every adapter implements a base interface with four methods: connect, discover capabilities, read state, write commands. The adapter registry handles discovery — probes the network, identifies connected equipment, binds the right adapter.
Above the adapter layer sits the state transformer, which converts protocol-native telemetry into ARMP messages — a common format that the coordination layer can reason about. Below it sits vendor-specific connection logic. The adapter is the translation layer between the two.
The result: the MARL engine never knows whether it’s controlling a CoolIT CDU over Modbus or a Vertiv unit over Redfish. Same observation vector. Same action space. Same physics. Only the adapter knows the difference.
Coordination across protocol boundaries
Protocol fragmentation doesn’t just make data collection harder. It makes coordinated control harder.
When a thermal zone agent decides to increase cooling — because it has observed a temperature trend that will hit a warning threshold in 9 minutes — it issues a setpoint change to a CRAC unit. That command travels through the ARMP coordination layer, through the BACnet adapter, and arrives at the CRAC controller as a BACnet Write Property request. Round-trip latency depends on BACnet network topology, the controller’s scan rate, and whether the setpoint change triggers a compressor state change (which adds mechanical latency).
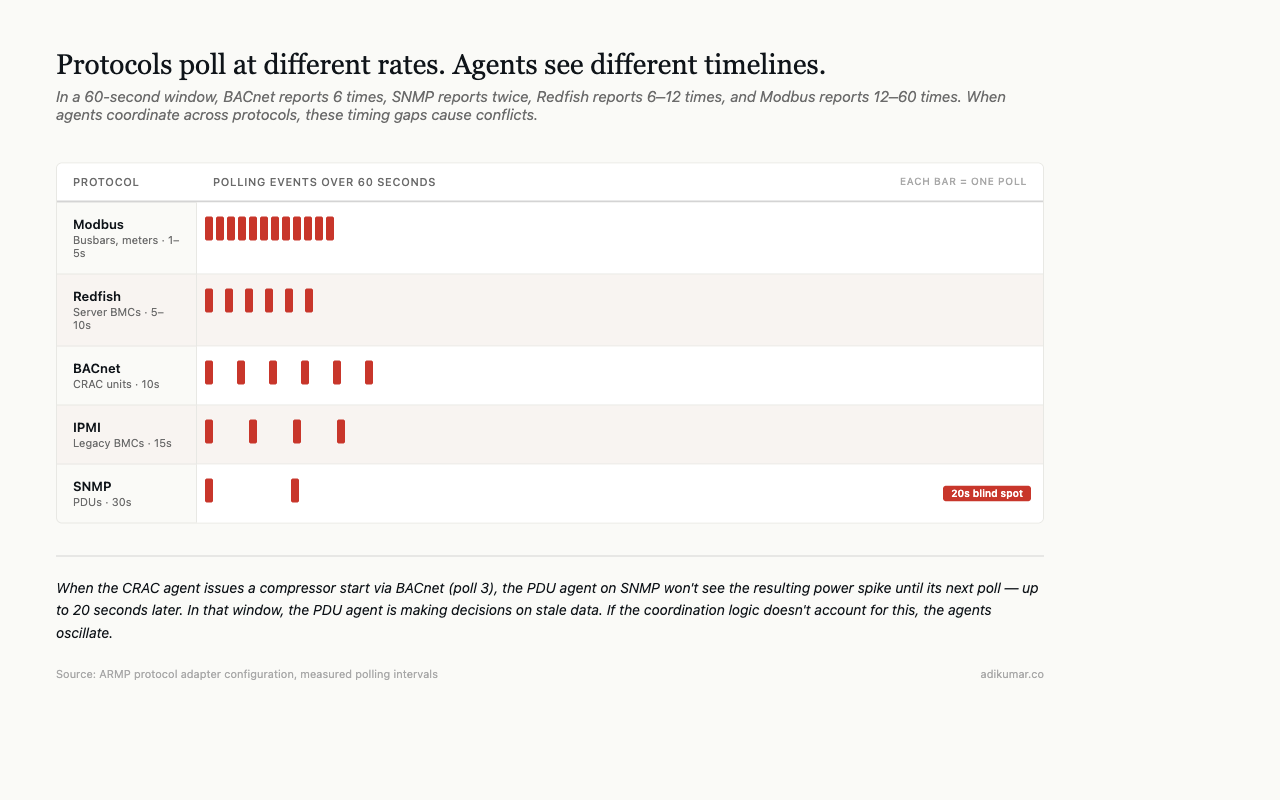
Meanwhile, a PDU agent on the same thermal zone is observing power draw through SNMP. It sees the cooling power increase (compressor kicked in) and has to decide whether to flag a power constraint. But SNMP polling is every 30 seconds and BACnet polling is every 10 seconds. The PDU agent sees the power spike 20 seconds after the CRAC agent caused it.
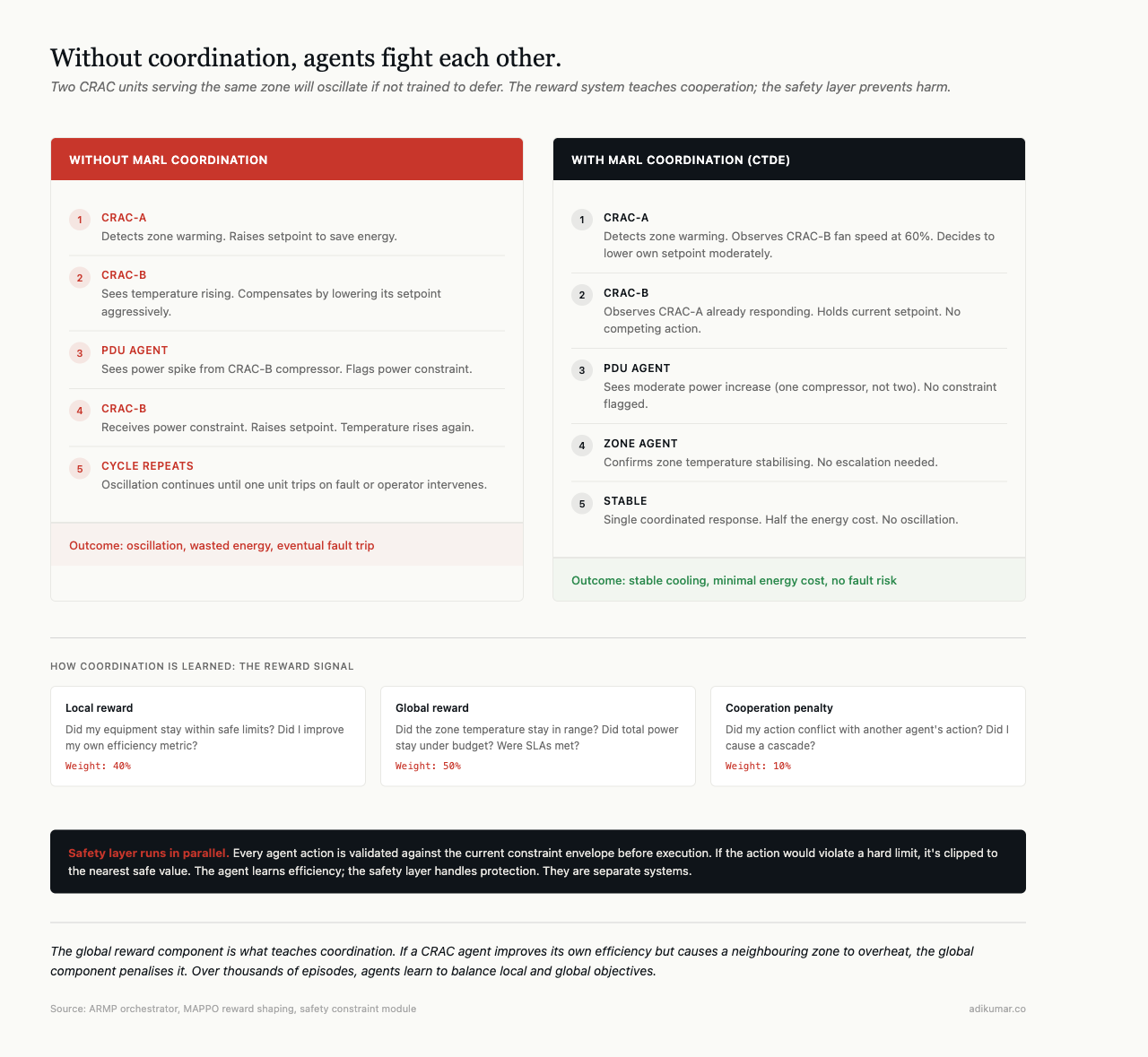
Without accounting for these protocol-level timing differences in coordination logic, agents fight each other. Power agent sheds load that cooling agent just added. Cooling agent sees the shed and reduces output. Temperature rises. This oscillation is real and it happens in production.
Where to start
Start with the adapters. Not the AI. Map every protocol on your floor, understand the polling intervals, understand the command latency, understand what each device actually reports versus what the datasheet claims. Build the translation layer first. Make it boring and reliable.
The AI layer is straightforward once the data is clean, consistent, and timely. Making eight protocols look like one is the actual work.
This is part of a series on building autonomous data centre management systems. The views are my own.
