Every data centre operator runs with safety margins. Thermal ceilings 10-15 degrees below equipment limits. Power caps at 80% of rated capacity. Redundancy ratios calculated for worst-case simultaneous failure. These margins exist for good reason — exceeding a thermal limit or tripping a breaker is expensive and sometimes dangerous.
But the margins are static, and operating conditions are not.
At 3am on a Tuesday in January, a facility in Northern Europe runs at 40% compute utilisation with outside air at -2C. The thermal ceiling is set at 85F because that’s the safe limit in August when outside air is 32C and every rack is at peak load. The power cap is at 80% because that’s the safe limit with both utility feeds active and the BESS at minimum charge. The redundancy ratio assumes N+1 on every cooling unit because maintenance windows are unpredictable.
The gap between the static limit and the actual safe limit at any given moment — that’s grey space. Real capacity the operator owns, has paid for, and isn’t using.
This is the problem that led me to build a working prototype of what I’m calling ARMP (Adaptive Resource Management Protocol) — a coordination layer that sits above device-level protocols like Redfish and BACnet. Existing protocols tell you what individual equipment is doing. ARMP lets grey space (power, cooling, physical plant) and white space (compute, workloads, GPUs) communicate constraints, capacity, and intent to each other bidirectionally. The cooling system knows a training job is about to spike. The workload scheduler knows cooling in Zone A is constrained. The facility operates as one system rather than two that share a building.
A protocol like this would ultimately need to come from a consortium — OCP, IEC, or a dedicated working group — not a single vendor. ARMP is a placeholder name for a working implementation of the concept.
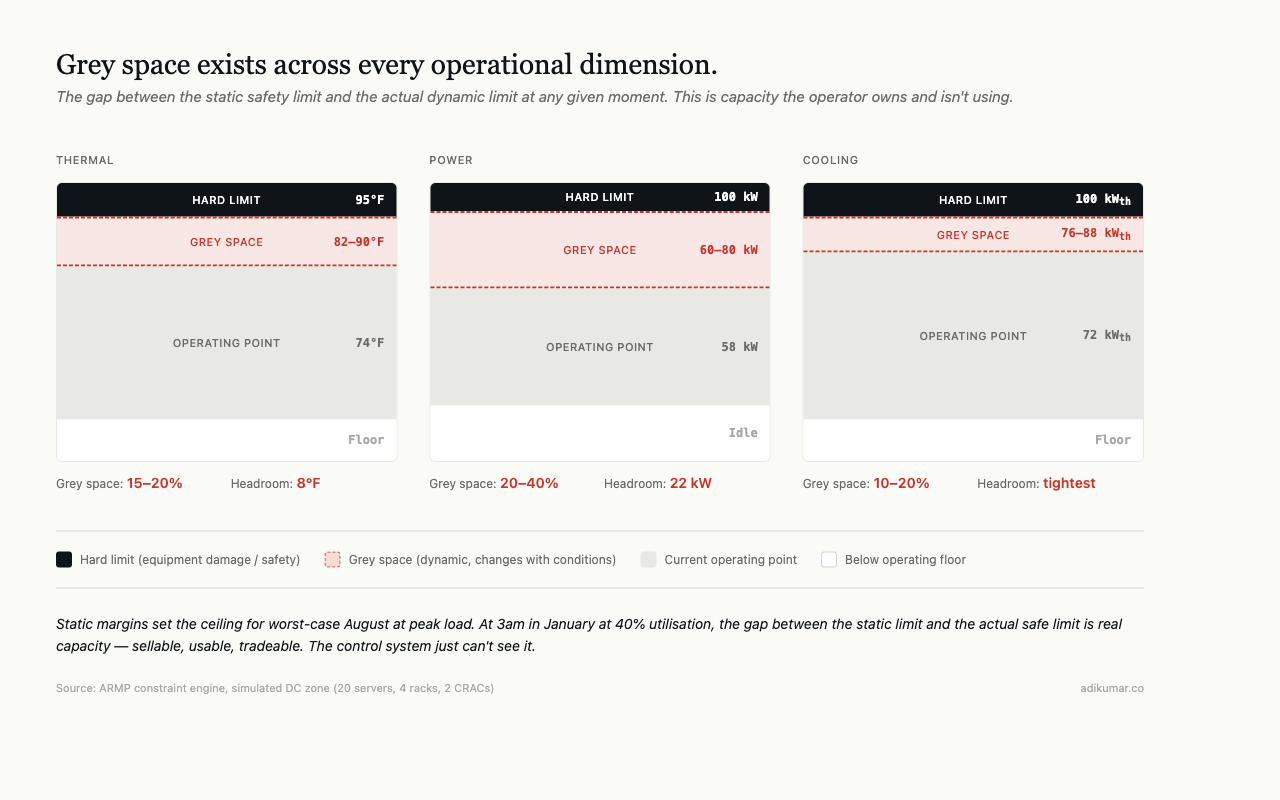
How much capacity is stranded
In ARMP, we instrumented a simulated data centre zone with 20 servers across 4 racks, served by 2 CRAC units at 50kW each. We tracked the gap between static and dynamic limits across thermal, power, and cooling dimensions continuously.
At any given moment: 15-30% of thermal headroom was unused. Power headroom was wider — 20-40% depending on workload mix. Cooling capacity was tightest, typically 10-20% above actual demand.
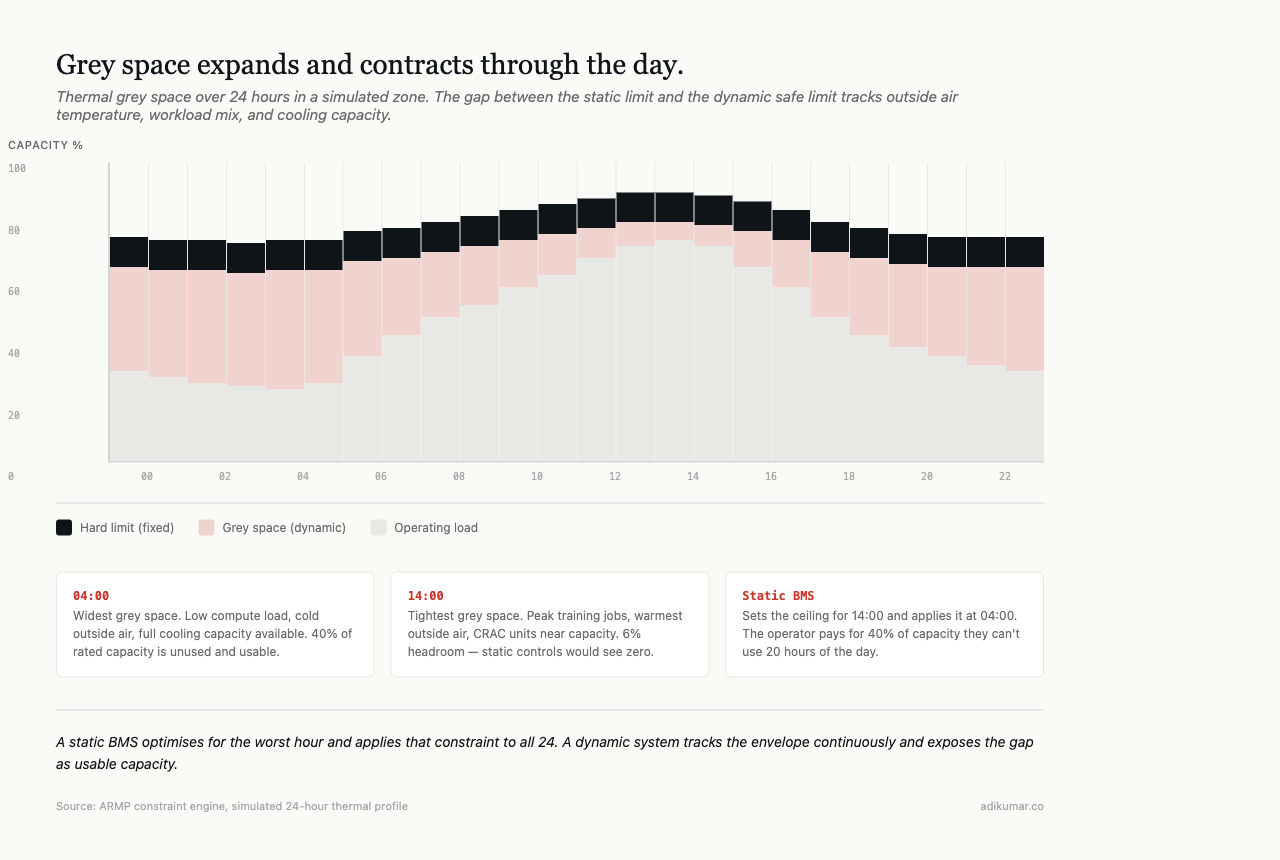
This capacity could be sold, used for burst compute, or traded for efficiency. It sits idle because the control system doesn’t know it exists.
Why static margins persist
Dynamic constraint management is hard to do safely. If you raise the thermal ceiling from 85F to 90F because conditions allow it, you need certainty that you can bring it back down before conditions change. A workload spike, an outside air temperature swing, a cooling unit going into maintenance, a utility feed dropping — any of these can happen in minutes. The control system needs to detect the change, recalculate the safe operating envelope, and adjust constraints before equipment exceeds real limits.
Traditional BMS and DCIM systems don’t do this. They set thresholds at commissioning, maybe adjust seasonally, and leave them. The engineer who set the threshold optimised for the worst case they could imagine, not for current conditions.
Dynamic constraint management in practice
In ARMP, the constraint engine runs continuously alongside the MARL agents. It maintains a real-time model of the safe operating envelope across six dimensions: thermal (per zone and per rack), power (per PDU, per circuit, per feed), cooling (per CRAC, per CDU, per zone), UPS (battery state, load level, efficiency curve), workload (SLA commitments, migration feasibility), and physical plant (outside air, humidity, utility status).
Each dimension has three boundaries:
- Hard limit: equipment damage or safety compromise. Never exceeded.
- Soft limit: operational risk increases. Can be exceeded temporarily with monitoring.
- Current operating point: where the system is right now.
Grey space is the distance between current operating point and soft limit. The constraint engine calculates it continuously and exposes it to the MARL agents as part of their observation space.
A cooling agent doesn’t just see “temperature is 74F.” It sees: temperature is 74F, soft limit is 82F given current conditions, grey space is 8F, and based on thermal trend and workload schedule, grey space will shrink to 4F in the next 20 minutes. That observation lets the agent make efficiency decisions — reduce fan speed, save power — that a static threshold cannot support.
Thermal event prevention
In our end-to-end demo, the system prevented a thermal event that static controls would have missed. A training job on Rack-001 drove utilisation from 45% to 85%. Static controls would have waited for the 85F alarm and then reacted. The MARL system detected the temperature trend at 77F (WARNING), predicted it would reach CRITICAL in 9.5 minutes, and proactively migrated two workloads to Rack-004 while dropping the CRAC setpoint by 2F.

Total response time: under 30 seconds from detection to action. Temperature peaked at 77.4F and recovered to 73.6F. CRITICAL was never reached.
Energy result: 16.7% savings over the demo period, projected to $290/week per zone at scale. Most of that comes from cooling optimisation — running CRAC units closer to actual demand rather than at the static worst-case setpoint.
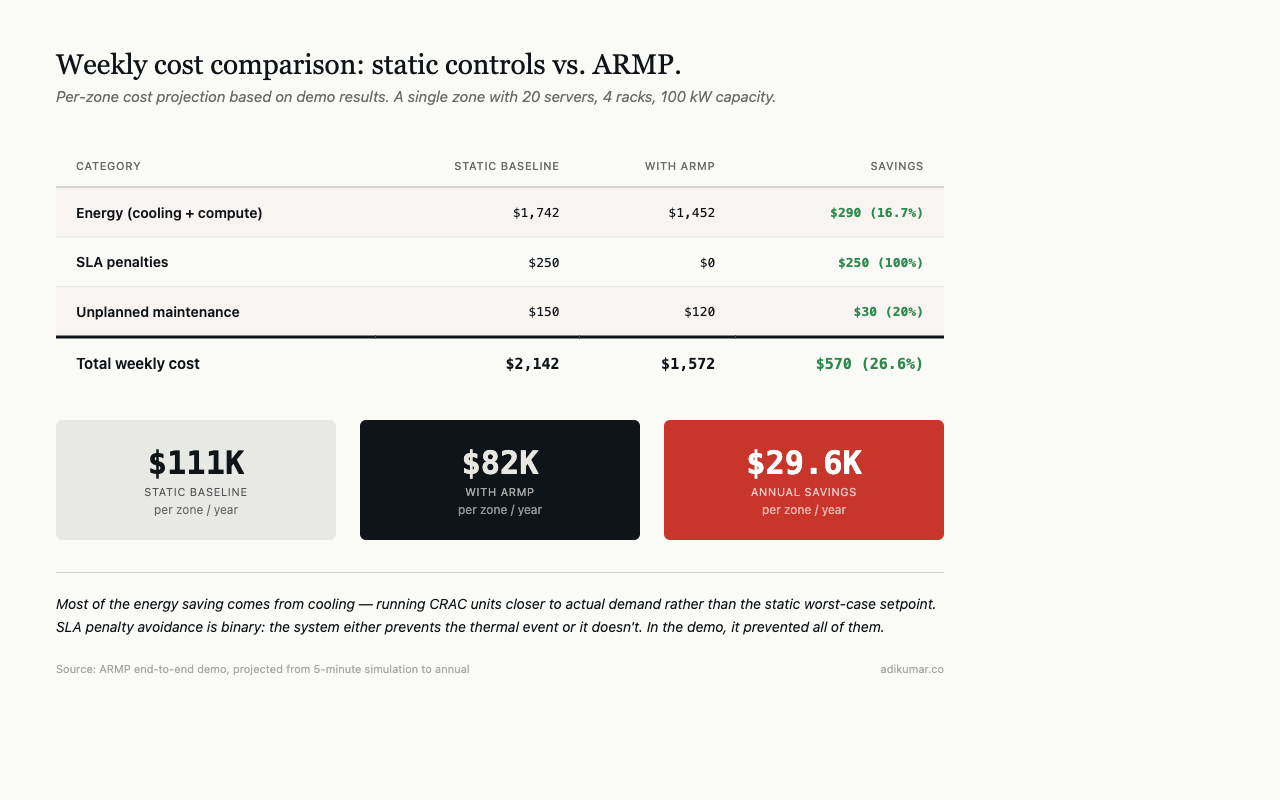
The commercial shift
Grey space management changes the conversation between operations and commercial teams. Instead of “we have X MW of capacity and it’s Y% sold,” the conversation becomes: we have X MW of static capacity, but at current conditions we have X+Z MW of dynamic capacity available for the next N hours.
Z is sellable. Burst capacity for cloud tenants. Scheduling flexibility for AI training jobs. Demand response capacity for utility grid programmes. It exists right now in every facility — the question is whether the control system can see it, and whether the operator trusts it enough to use it.
Building that trust is the harder problem. The technology works. Operational confidence takes longer.
This is part of a series on building autonomous data centre management systems. The views are my own.
