ARMP (Adaptive Resource Management Protocol) is a coordination layer that sits above device-level protocols like Redfish and BACnet. Its job: let grey space (power, cooling, physical plant) and white space (compute, workloads, GPUs) communicate constraints to each other in real time, so the facility operates as one system. A protocol like this would ultimately need to come from a consortium, not a single vendor — ARMP is a working prototype of the concept.
At its core are 32 software agents, each controlling a specific piece of equipment, learning to coordinate through experience. Two UPS agents. Four PDU agents. Four CRAC agents. Two thermal zone agents. Twenty workload agents (one per server). Each agent sees only its own local sensors and makes its own decisions. No central brain in production. The agents learned coordination during training; in production they run independently.

The architecture is CTDE — Centralised Training, Decentralised Execution. During training, a central critic sees everything and helps all agents learn together. During execution, each agent runs alone. No central bottleneck. No single point of failure. If one agent goes down, the others keep running.
Agent types
UPS agents (2) manage uninterruptible power supplies. They observe 13 dimensions of state: load level, efficiency curve, input/output voltage, battery state of charge, temperature, transfer switch status, and derived metrics. Their action space has 3 dimensions: eco-mode threshold, battery charge rate, and load-sharing ratio between redundant units.
UPS efficiency curves are non-linear — a typical double-conversion unit is most efficient at 40-60% load. Below that, fixed losses dominate. Above that, thermal losses climb. The agent learns to shift load between units to keep both in the efficient band rather than running one at 80% and the other at 20%.
PDU agents (4) control power distribution. They see 15 dimensions: per-circuit current draw, voltage, power factor, breaker status, aggregate load. Action space is 7 dimensions — load balancing across circuits, current limits per circuit, and maintenance flagging.
The interesting problem here is phase balancing. A three-phase PDU with unbalanced loading wastes capacity on the underloaded phases. The agent learns to flag imbalanced circuits and recommend workload redistribution.
CRAC agents (4) are the most consequential. They observe 17 dimensions: supply air temperature, return air temperature, fan speed, compressor state, coolant flow rate, setpoint, outside air enthalpy, and cross-agent observations (what neighbouring CRAC units are doing). Action space has 3 dimensions: setpoint adjustment, fan speed override, economiser mode.
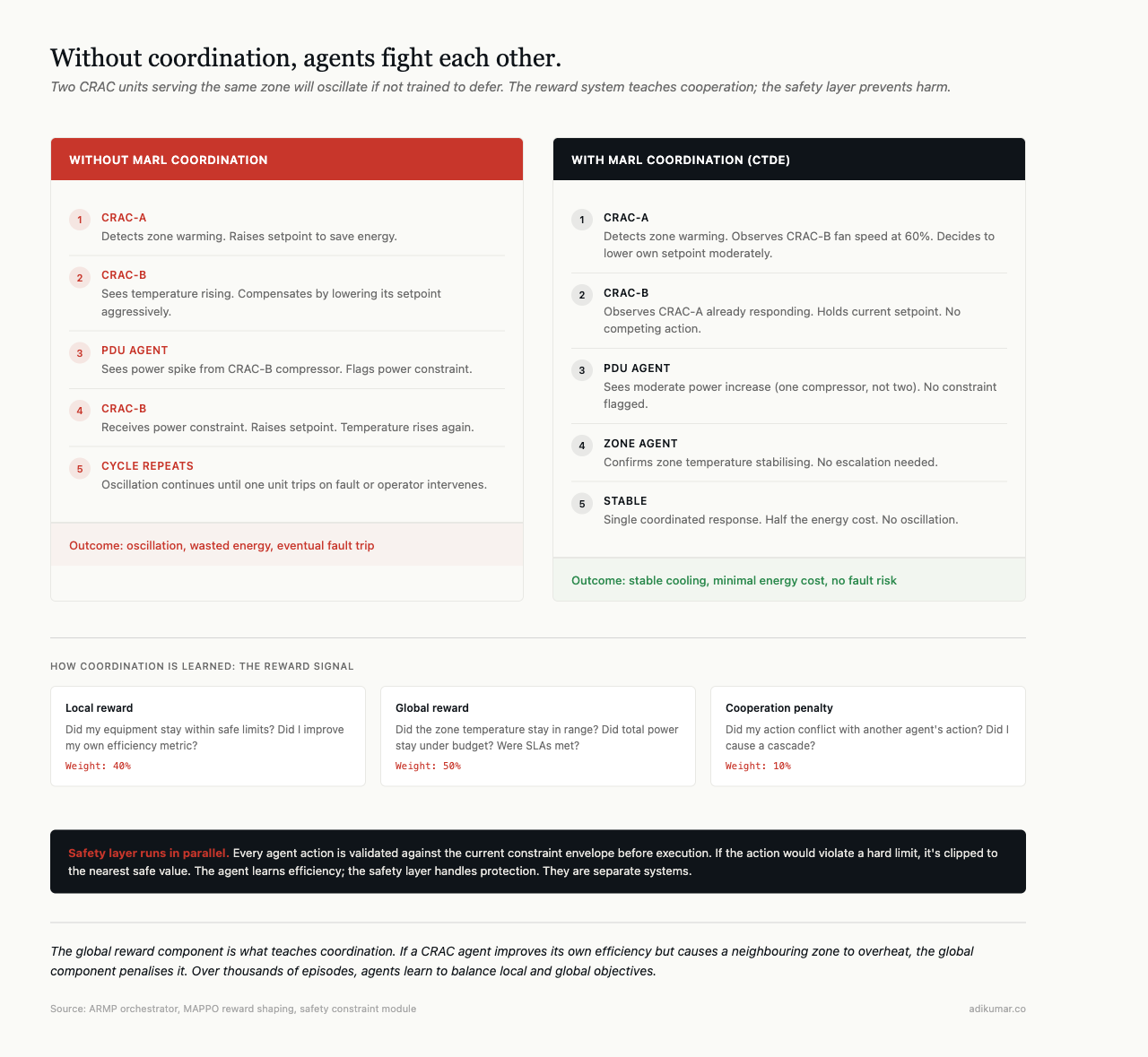
Two CRAC units serving the same zone will fight each other if not coordinated — one raises its setpoint, the other compensates by lowering, oscillating until one trips on a fault. During training, the central critic teaches them to coordinate. In production, they coordinate through shared observations: each agent sees what the neighbour is doing, and they’ve learned to defer rather than compete.
Thermal zone agents (2) sit above the equipment agents. They see 27 dimensions — aggregate temperatures across racks, power draw patterns, workload types, time-of-day features. They don’t control equipment directly. They set zone-level targets that CRAC and PDU agents treat as soft constraints. Strategic layer above the tactical layer.
Workload agents (20, one per server) observe 12 dimensions each: CPU utilisation, memory utilisation, GPU utilisation (if present), power draw, inlet temperature, SLA parameters. Action space has 4 dimensions: workload migration requests, power capping, scheduling priority, and cooling attention flags.
All 20 workload agents use parameter sharing — same learned policy. This works because every server has the same observation and action structure. The policy generalises across servers; individual behaviour emerges from different observations.
Coordination without a central brain
The coordination mechanism is the reward system. During training, each agent receives a weighted combination of local and global objectives:
- Local: Did my equipment stay within safe limits? Did I improve efficiency?
- Global: Did zone temperature stay in range? Did total power stay under budget? Were SLAs met?
The global component teaches coordination. If a CRAC agent improves its own efficiency by raising its setpoint but causes a neighbouring zone to overheat, the global component penalises it. Over thousands of training episodes, agents learn to balance local and global objectives.
In production, agents don’t receive rewards — they execute learned policies. But those policies encode the coordination patterns from training. A CRAC agent that learned “if my neighbour’s fan speed is above 80%, lower my setpoint to help” continues doing that without a central coordinator.
Conflict resolution
Agents sometimes want contradictory things. Cooling agent wants more power for the compressor. Power agent wants less total draw because a demand charge threshold is approaching. Workload agent wants to keep running because the SLA deadline is in 2 hours.
The orchestrator handles this during training through action coordination — detecting conflicts and applying priority rules. Cooling safety trumps power efficiency. SLA commitments trump cooling efficiency. Equipment protection trumps everything.
In production, a safety checker runs as a parallel process that can veto any agent action violating a hard constraint. Agent proposes an action. Safety checker validates it against the current constraint envelope. If it passes, the action executes. If not, the action is clipped to the nearest safe value.

This separation means agents can be aggressive in optimisation without risk. The safety layer is independent of the learning layer. Agents don’t need to learn safety — they learn efficiency, and the safety layer handles the rest.
16.7% energy savings in practice
Demo environment: 20 servers, 4 racks, 2 CRAC units, 100kW total capacity. The MARL system reduced energy consumption by 16.7% compared to the static-control baseline. Projected over a week: $290 in energy savings and $250 in avoided SLA penalties per zone.
Three learned behaviours drove most of the savings:
Predictive cooling. CRAC agents learned to anticipate temperature spikes from workload patterns. Preemptive cooling at moderate output is cheaper than reactive cooling at maximum.
UPS load balancing. UPS agents learned to shift load between units to keep both in the 40-60% efficiency band, reducing conversion losses by 3-5%.
Workload migration. Workload agents learned to proactively move jobs away from thermally stressed racks before temperatures hit warning thresholds, reducing the frequency and severity of cooling emergencies.
These behaviours emerged from training. We didn’t program them — the reward function favoured them.
What this doesn’t do yet
The system runs in simulation. We’ve validated the physics models against published thermal and power data, and the results are consistent. But running 32 RL agents against live infrastructure is a different proposition. Sensor noise, communication failures, equipment that doesn’t respond as modelled, and the hundred other things that don’t happen in a simulator.
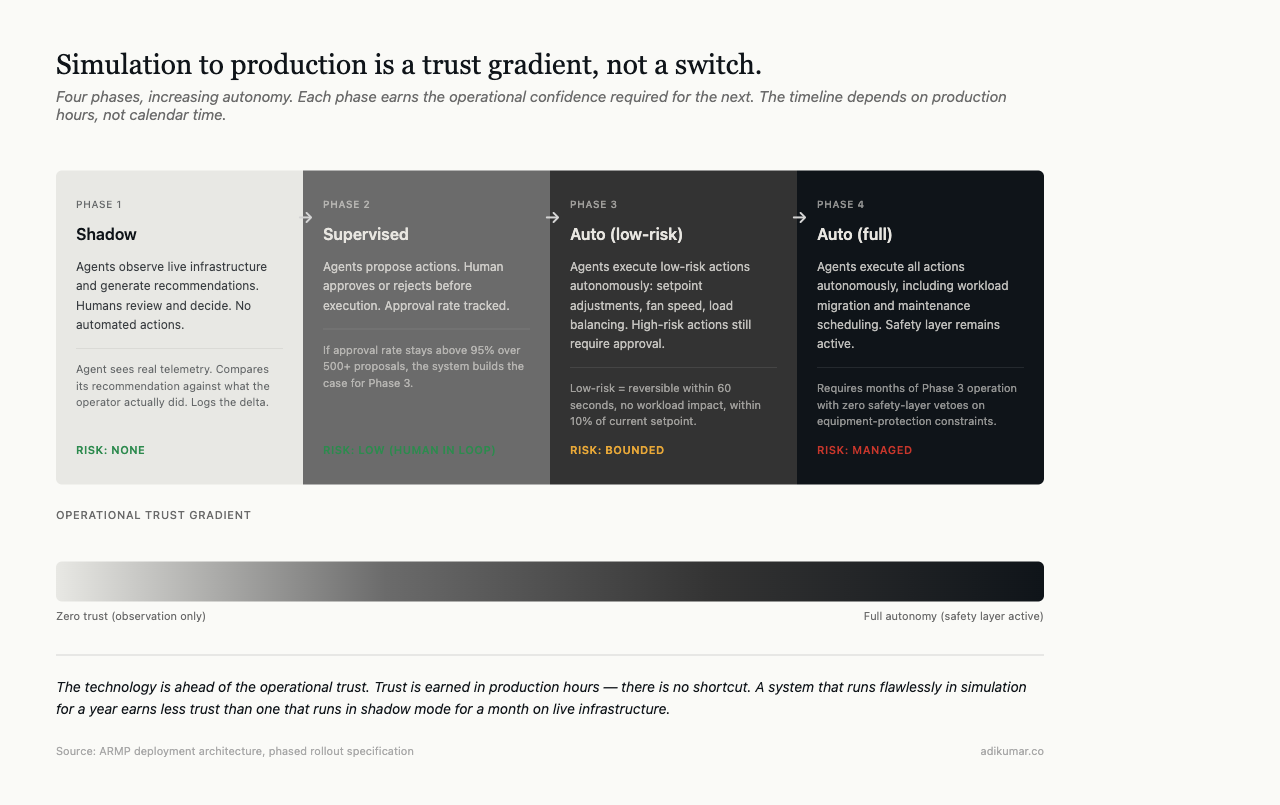
The path forward is phased: shadow mode (agents observe and recommend, humans execute), then supervised mode (agents execute, humans approve), then autonomous for low-risk actions (setpoint adjustments, load balancing), eventually autonomous for higher-risk actions (workload migration, maintenance scheduling).
That path takes time. The technology is ahead of operational trust, and operational trust is earned in production hours, not in papers.
This is part of a series on building autonomous data centre management systems. The views are my own.
