
Update: Since this essay was published, the picture has moved, and in a direction worth recording. The first-generation divergence it describes NVIDIA's 800 V unipolar reference and OCP Mt. Diablo's ±400 V bipolar default was real, and it traces to a shared starting point: both camps began at the rack, and both selected their voltages to inherit the existing EV supply chain rather than build a new one. Where they initially split was topology, not intent. What changed the trajectory was the entry of the electrical-equipment manufacturers - Designing to these architectures at volume, the cost of a fragmented ecosystem would became concrete: duplicated R&D across incompatible designs, a thinner supplier pool behind each component, and a slower, more expensive path to the safety standards the whole category needs.
The response has been coordination rather than a winner-takes-all standards fight. IT players and electrical OEMs have converged in the OCP 800VDC subcommittee and engaged with with standards bodies, with the explicit goals of underwriting a safe transition, keeping a diversified supplier base behind every "brick" of the stack, and sparing manufacturers the burden of building to radically different specifications. That is a better outcome than the divergence the essay captured at a single point in time, and it is worth saying so. Original essay follows
The trade press writes about "the move to 800 VDC" as if it's one thing.
There are at least two competing architectures wearing that label right now, and they don't look much alike. NVIDIA's reference design rectifies at row scale and hands a locked 800 VDC bus to a vertically integrated compute rack. The Open Compute Project's Mt. Diablo specification, authored by Meta, Google, and Microsoft, rectifies in a sidecar power rack adjacent to the IT rack, supports a configurable output (bipolar ±400 V or unipolar 800 V), and accepts any accelerator that complies with the spec. Both deliver 800 V of usable potential. The similarities end there.
This essay is about why that distinction matters more than it looks, and what it tells us about the shape of the data centre power industry over the next five years. Worth saying up front: at scale, most hyperscalers will operate both architectures inside the same estate — not as a hedge, but because their workload mix and silicon mix demand it. The choice isn't binary; the primary architecture choice is what shapes everything else.
A note on terminology, continued
Essay 1 made the case that calling this transition "HVDC" is technically wrong under IEC 60038. I'll use 800 VDC for the unipolar architecture, ±400 VDC or Mt. Diablo for the bipolar one, and the DC transition when referring to the broader industry shift. All of these sit firmly inside the LVDC envelope. The trade press will keep calling it HVDC. We will keep being correct.
1. The two architectures, sketched
The cleanest way to see the difference is to draw both at the same scale, with the same components, and look at what's structurally different.
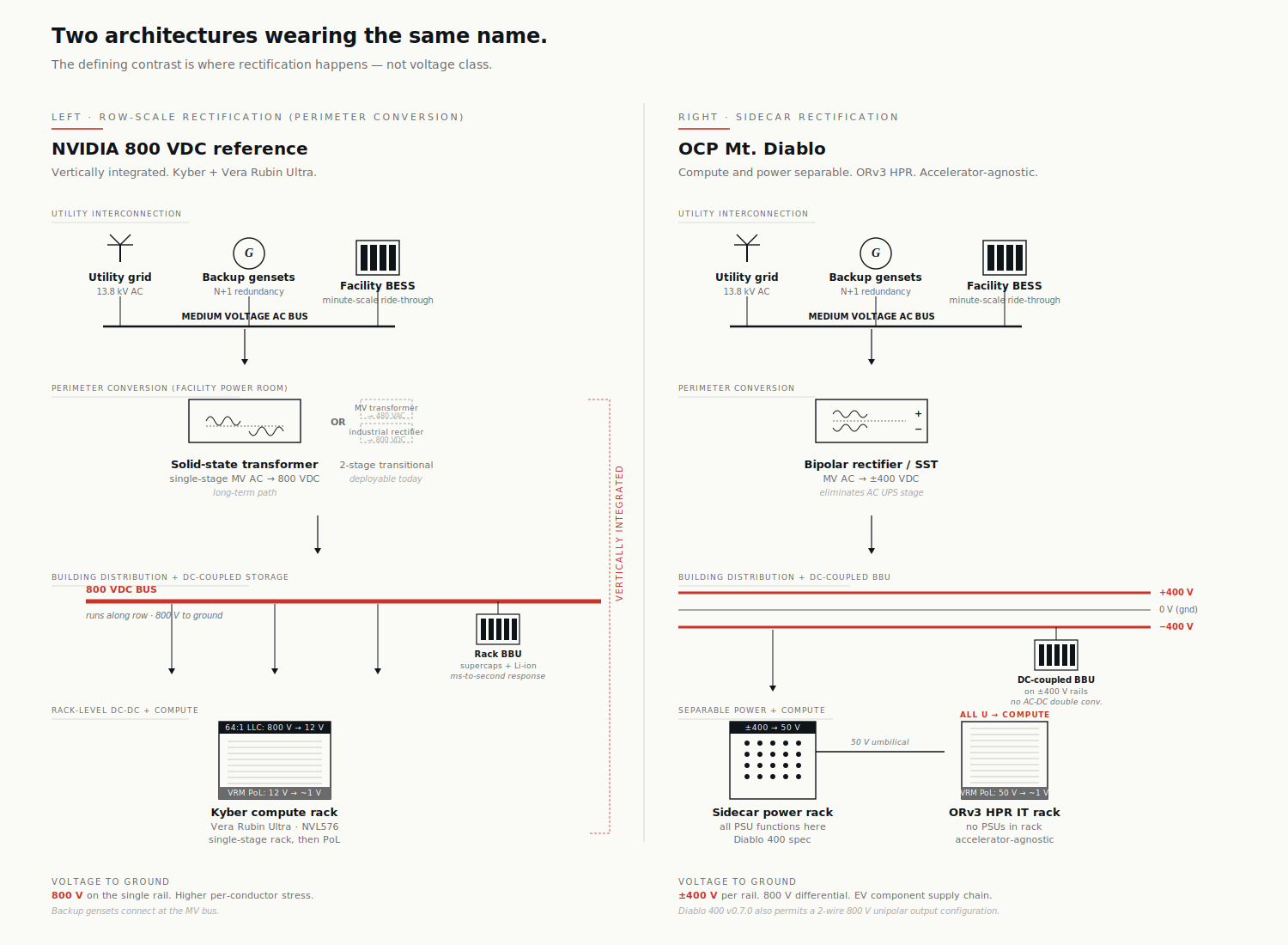
NVIDIA 800 VDC reference (row-scale rectification). Medium-voltage AC arrives from the utility, hits a solid-state transformer at the building perimeter or at the row level, and emerges as a single bus at +800 V to ground. That bus runs along the row to each compute rack, where compact step-down converters deliver the 50 V class to the GPU. The compute and power conversion are designed as one vertically integrated system: the Kyber rack, designed for the Vera Rubin Ultra accelerator, expects 800 VDC at the rack inlet and won't accept anything else.
OCP Mt. Diablo (sidecar rectification, configurable output). Same medium-voltage AC input, but rectification happens in a dedicated power rack sitting next to one or more IT racks rather than at row scale. The IT racks themselves contain no PSUs — every rack unit is available for accelerators and scale-up switching. The Diablo 400 specification permits two output configurations from the sidecar: a three-wire bipolar arrangement at +400 V, 0 V (common), and −400 V, or a two-wire unipolar arrangement at 800 V and return. The IT racks are ORv3 HPR (Open Rack v3 High Power Rack) and accept any accelerator that complies with the spec — NVIDIA's parts work, but so do Trainium, MTIA, Maia, and AMD's MI series.
The defining contrast is where rectification happens — sidecar vs row — and whether compute is locked to a single accelerator family. The voltage-class debate (bipolar vs unipolar) sits inside Mt. Diablo as a configuration choice, not as the architectural fault line.
Same nominal usable voltage. Different rectification topology. Different stress to ground in the bipolar case. Different supply chain. Different commercial intent.
2. The dimensions that matter
Past the marketing, there are six dimensions where the architectures actually diverge.
| Dimension | NVIDIA 800 VDC reference | OCP Mt. Diablo |
|---|---|---|
| Rectification location | Row-scale (perimeter or row-level SST) | Sidecar (rack-adjacent power rack) |
| Default rack output | 800 V unipolar | ±400 V bipolar (800 V unipolar permitted) |
| Conductor count to a rack | 2 (positive + return) | 3 (+400, common, −400) in default config |
| Supply chain leverage | Purpose-built 800 V parts | EV-derived 400 V parts (default config) |
| System scope | Vertically integrated AI factory | Compute and power as separable building blocks |
| Accelerator compatibility | NVIDIA Vera Rubin family | Any ORv3 HPR–compliant accelerator |
Three of those dimensions deserve real attention before we move on, because the marketing on each side oversells them.
On output voltage class. The Diablo 400 spec (v0.7.0, March 2026) explicitly permits both bipolar and unipolar output from the sidecar. So the "NVIDIA = 800 V, Mt. Diablo = ±400 V" framing in trade press is incomplete. The default and most-promoted Mt. Diablo configuration is bipolar ±400 V — that's the configuration that captures the EV supply chain argument. But operators that want unipolar 800 V output can get it within the same spec. The real contrast is sidecar vs row, not bipolar vs unipolar.
On fault behaviour. It's tempting to frame Mt. Diablo's bipolar option as a reliability win — half the bus stays alive when one rail faults to ground. In theory, yes. In practice, most protection schemes will trip the entire bus on a single pole-to-ground fault for safety reasons, regardless of whether the surviving rail could carry partial load. The bipolar advantage is real in fault energy (each conductor sits at 400 V to ground rather than 800), but the "ride-through on one rail" framing is more aspirational than operational at this point.
On conductor count. Bipolar ±400 V needs three conductors plus careful neutral handling per rack; unipolar 800 V needs two. At 600 kW+ per rack — where the industry is heading — this is not a trivial difference for busway sizing, distribution complexity, and per-rack copper capex. More on this in §6.
The dimension that matters most for the next three years, though, isn't any of those. It's the supply chain.
3. Why ±400 V is really an EV play in disguise
Here's the under-discussed thing about Mt. Diablo's default bipolar configuration: 400 V isn't a number Meta and Google picked for technical elegance. They picked it because there's already a planet-scale supply chain for components rated at 400 V, built by the electric vehicle industry over the past decade. The Diablo 400 specification itself names this rationale — "selecting 400 VDC as the nominal voltage leverages the supply chain established by electric vehicles, for greater economies of scale, proven quality, and more efficient manufacturing."
A precision note before the argument: most BEV traction systems still use ~400 V battery packs (Tesla, BYD volume models, most Chinese EVs). The components inside an EV are not all rated to 400 V to ground — pack architecture, motor inverter topology, and isolation strategy all vary. But the discrete 400 V-class parts (IGBTs, SiC MOSFETs, capacitors, contactors, fuses, connectors) are produced at scale specifically because the EV industry needs them in this voltage class. Annual production of EV-grade 400 V power modules is in the millions of units across the major suppliers (Infineon, ST, Wolfspeed, ON Semi, Mitsubishi). The 400 V class as a standardized component design point really consolidated between 2015 and 2018 as second-generation EV platforms moved off bespoke voltages onto common ones. That curve has been compounding for a decade.
The 800 V class, by contrast, is much earlier. Yes, EV fast charging stations and 800 V powertrains (Porsche Taycan, Hyundai E-GMP, Lucid Air, Kia EV6) operate at this class but volumes are roughly an order of magnitude below the 400 V base, the components are different (rectifiers and chargers, not motor inverters), and the certification frameworks for stationary 800 V data centre equipment are still maturing.
The most cited recent UL milestone — ABB earning UL 98B certification for a 2 kV switch-disconnector in July 2025 — is illustrative precisely because of how narrow it is. That certification was for utility-scale solar, not data centres, and as the standards press noted at the time, UL 98B itself only tests up to 1500 V; ABB's 2 kV cert was a stretch case ahead of UL writing the broader voltage range into the standard. The standards extension to genuinely cover 800 V stationary data centre topologies, with the arc, protection, and isolation requirements that come with that environment, is an active area of work, not a settled one.
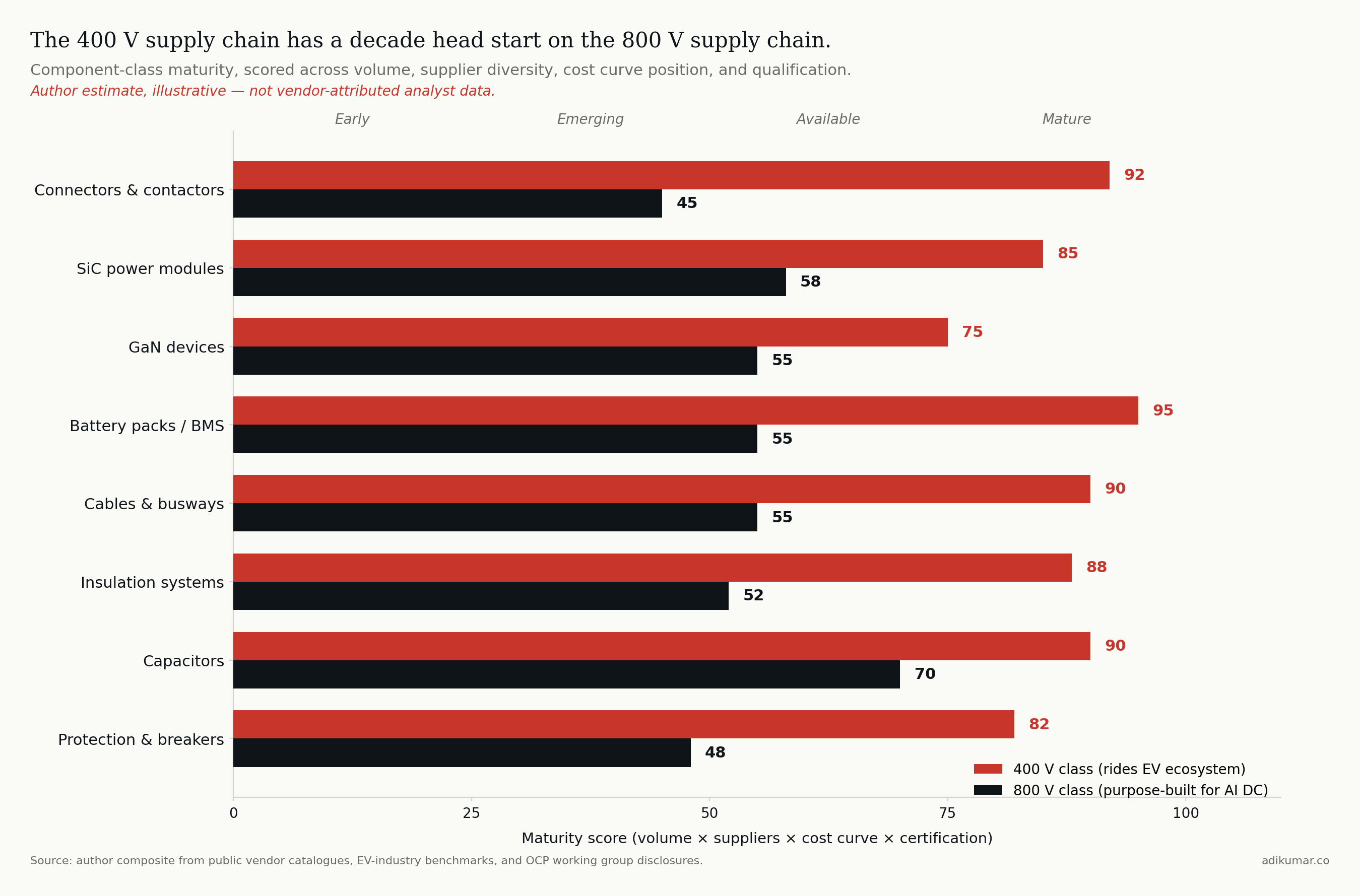
So when Meta, Google, and Microsoft jointly authored Mt. Diablo with bipolar ±400 V as the default configuration, they were doing something specific: they were borrowing the EV industry's component cost curve. By 2027 they'll be deploying a power architecture whose discrete components are riding a learning curve that started consolidating a decade ago, while NVIDIA's vendors will still be on the steeper early portion of an entirely new 800 V curve.
Update: Since this essay was published, the picture has moved, and in a direction worth recording. The first-generation divergence it describes NVIDIA's 800 V unipolar reference and OCP Mt. Diablo's ±400 V bipolar default was real, and it traces to a shared starting point: both camps began at the rack, and both selected their voltages to inherit the existing EV supply chain rather than build a new one. Where they initially split was topology, not intent. What changed the trajectory was the entry of the electrical-equipment manufacturers - Designing to these architectures at volume, the cost of a fragmented ecosystem would became concrete: duplicated R&D across incompatible designs, a thinner supplier pool behind each component, and a slower, more expensive path to the safety standards the whole category needs.
The response has been coordination rather than a winner-takes-all standards fight. IT players and electrical OEMs have converged in the OCP 800VDC subcommittee and engaged with with standards bodies, with the explicit goals of underwriting a safe transition, keeping a diversified supplier base behind every "brick" of the stack, and sparing manufacturers the burden of building to radically different specifications. That is a better outcome than the divergence the essay captured at a single point in time, and it is worth saying so. Original essay follows
4. The unbundling pattern (and which layers are real)
Mt. Diablo is the visible piece of a larger pattern: hyperscalers systematically unbundling NVIDIA's vertical stack at every layer where they can.
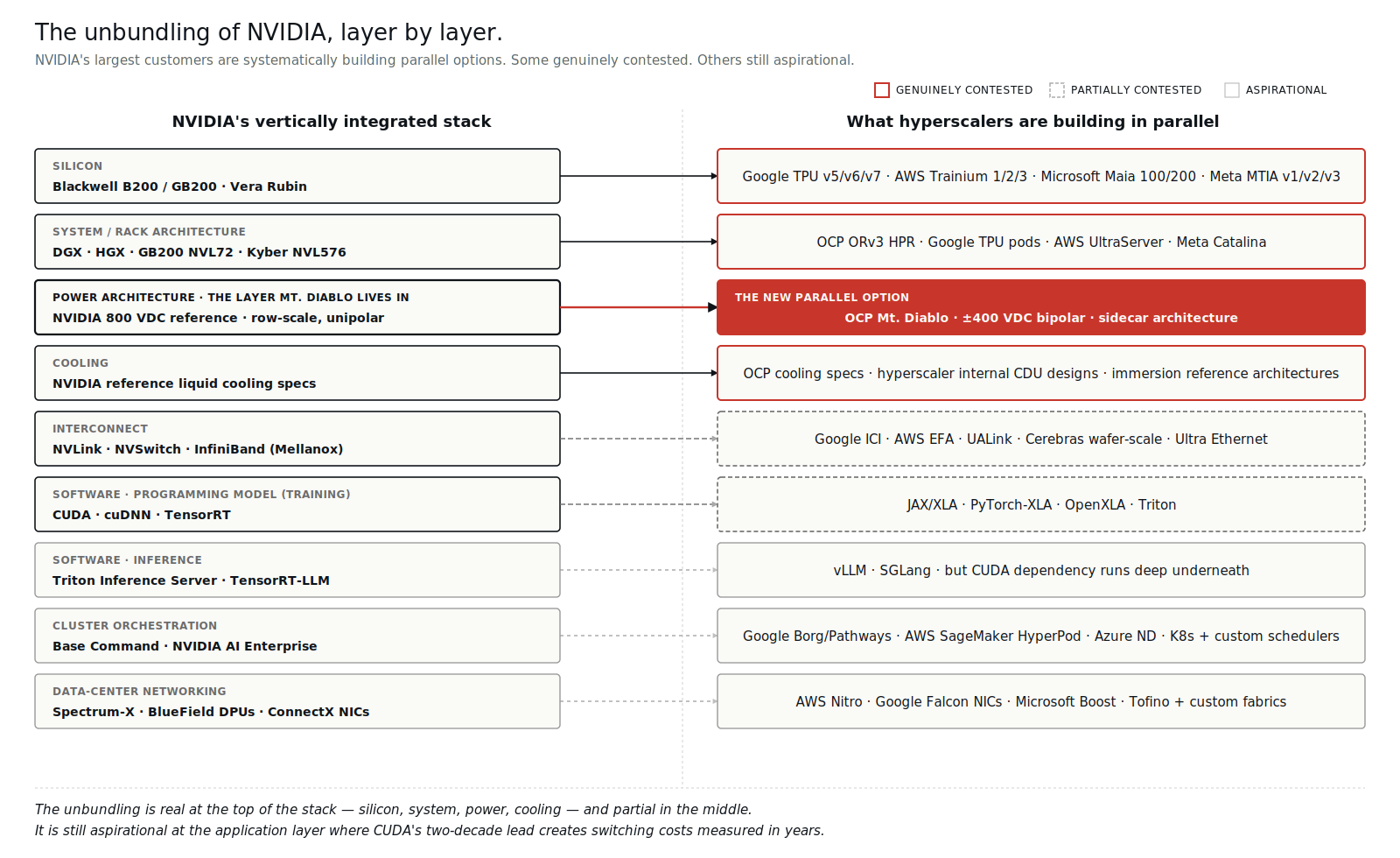
But the framing "alternatives exist at every layer" is doing work it shouldn't. Some of those alternatives are genuinely contested with real production deployment behind them. Others are aspirational specs with limited silicon to back them. Worth being precise about which is which:
Genuinely contested (real production volume, real deployment): - Silicon: Google TPU (a decade of internal deployment, now v7 Ironwood in volume), AWS Trainium 3, Meta MTIA v3, Microsoft Maia 200. NVIDIA's data centre share is projected to drop from ~86% in FY2025 toward ~75% by end of 2026, with custom ASIC volume growing at roughly 45% CAGR through 2028. - Form factor: OCP ORv3 HPR is shipping at scale across Meta, Google, Microsoft fleets. NVIDIA reference systems still dominate neoclouds. Genuinely split. - Power: NVIDIA 800 VDC vs. Mt. Diablo. The fight this essay is about.
Partially contested (real specs, limited silicon, dependent on future tape-outs): - Networking: Google ICI is real and at scale internally, but Ultra Ethernet Consortium specs have shipped while UEC silicon volume remains modest. NVLink and InfiniBand still dominate in non-Google deployments. - Software at training: JAX and PyTorch-XLA are credible, but the developer base remains small relative to CUDA. OpenXLA matters strategically but commands a fraction of CUDA's ecosystem mindshare.
Aspirational (specs exist, production is the open question): - Software at inference: vLLM and SGLang have meaningful production deployment, but the dependence on CUDA underneath is real for any workload that doesn't have a dedicated compiler team.
The honest summary: the unbundling is real at the top of the stack (silicon, form factor, power) and partial in the middle (networking, training software). It's still aspirational at the application layer where CUDA's two-decade lead, four-million-developer ecosystem, and framework-first integration create switching costs measured in years, not quarters.
5. The hyperscaler silicon investment
The unbundling at the silicon layer specifically deserves its own look, because it's the layer that funds all the others.
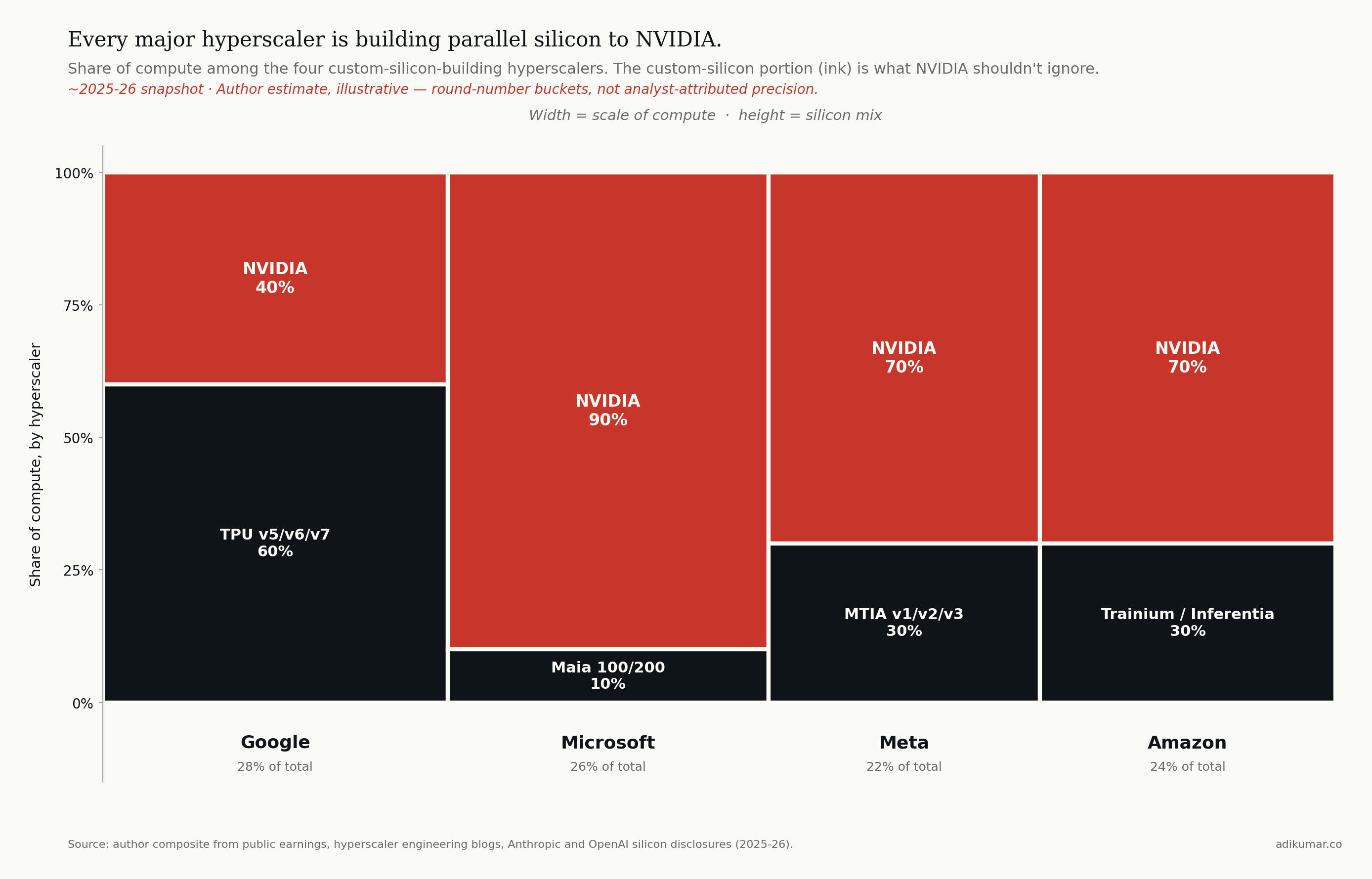
NVIDIA's data centre revenue ran $115B in FY2025 and is tracking toward $194B in FY2026. That number isn't going down — it's going up. But the share of new AI compute that goes to NVIDIA is declining, and the rate of decline is the part that matters. Consensus from Bloomberg Intelligence, TrendForce, SemiAnalysis, and Counterpoint converges on three claims that should shape power architecture decisions:
- NVIDIA's AI accelerator market share has declined from a peak of ~95% to an estimated 80-86% in 2025-2026, with most analysts forecasting further decline toward 75% by end of 2026 as custom ASIC volume scales.
- Custom ASIC shipments are projected to grow at roughly 45% CAGR through 2028, with shipments crossing GPU shipments in 2028 per Counterpoint.
- The displacement is most pronounced in **inference**, where custom ASICs are approaching parity in deployed FLOPs by 2027-2028. Frontier **training** remains NVIDIA-dominated and probably will through 2028, anchored by CUDA's ecosystem advantage and Vera Rubin's raw performance.
NVIDIA's revenue keeps growing in absolute terms because the AI compute pie is growing faster than the share shift. The displacement is real but asymmetric — share down, dollars up.
Three production realities matter most for power architecture decisions:
Google TPU v7 (Ironwood) entered volume production in late 2025, with industry sources estimating roughly 4.3M units shipping in 2026 and analyst forecasts pointing to cumulative deployment in the tens of millions across 2026-2028. Anthropic specifically has committed to deploying over one million Ironwood chips, representing more than a gigawatt of compute. Ironwood is designed and deployed in ORv3 HPR-class racks with sidecar power.
AWS Trainium 3 reached general availability in December 2025 at re:Invent, built on TSMC 3nm. The Trn3 UltraServer scales to 144 chips across 36 servers in a multi-rack configuration; the volume per-rack SKU (NL32x2 Switched) is 32 chips per rack. Project Rainier — AWS's earlier deployment of 500,000+ chips with Anthropic — was Trainium 2-based; Trainium 3 is the next generation and Anthropic is among the named launch customers.
Meta MTIA v3 is in full deployment for inference workloads (ranking, recommendations, ad serving). MTIA v4 is in fabrication.
Microsoft Maia 200 runs Copilot and Azure OpenAI Services internally. Microsoft also remains one of NVIDIA's largest Vera Rubin customers — the dual-track strategy is explicit, and the implication for power architecture is that Microsoft will operate both Mt. Diablo halls (for Maia) and 800 VDC halls (for Vera Rubin) inside the same data centre estate.
When the operator of the workload also controls the silicon, the bargaining position with the rest of the stack changes.
6. So which architecture wins?
Wrong question.
The right question: which architecture wins for which kind of operator?
There's also a real engineering case for the row-scale unipolar approach that the supply-chain argument tends to bury. At 600 kW+ per rack — where Vera Rubin Ultra and similar accelerators are heading — the unipolar 800 VDC bus uses fewer conductors and less copper than the bipolar default. Mt. Diablo in its default three-wire config needs three conductors plus careful neutral handling; unipolar needs two. At extreme rack densities this matters for busway sizing, distribution complexity, and per-rack capex on conductors alone. NVIDIA's 800 VDC pitch isn't pure supply-chain naïveté — there's a real density argument underneath. The supply chain economics may dominate for the next five years; the density economics may dominate beyond that.
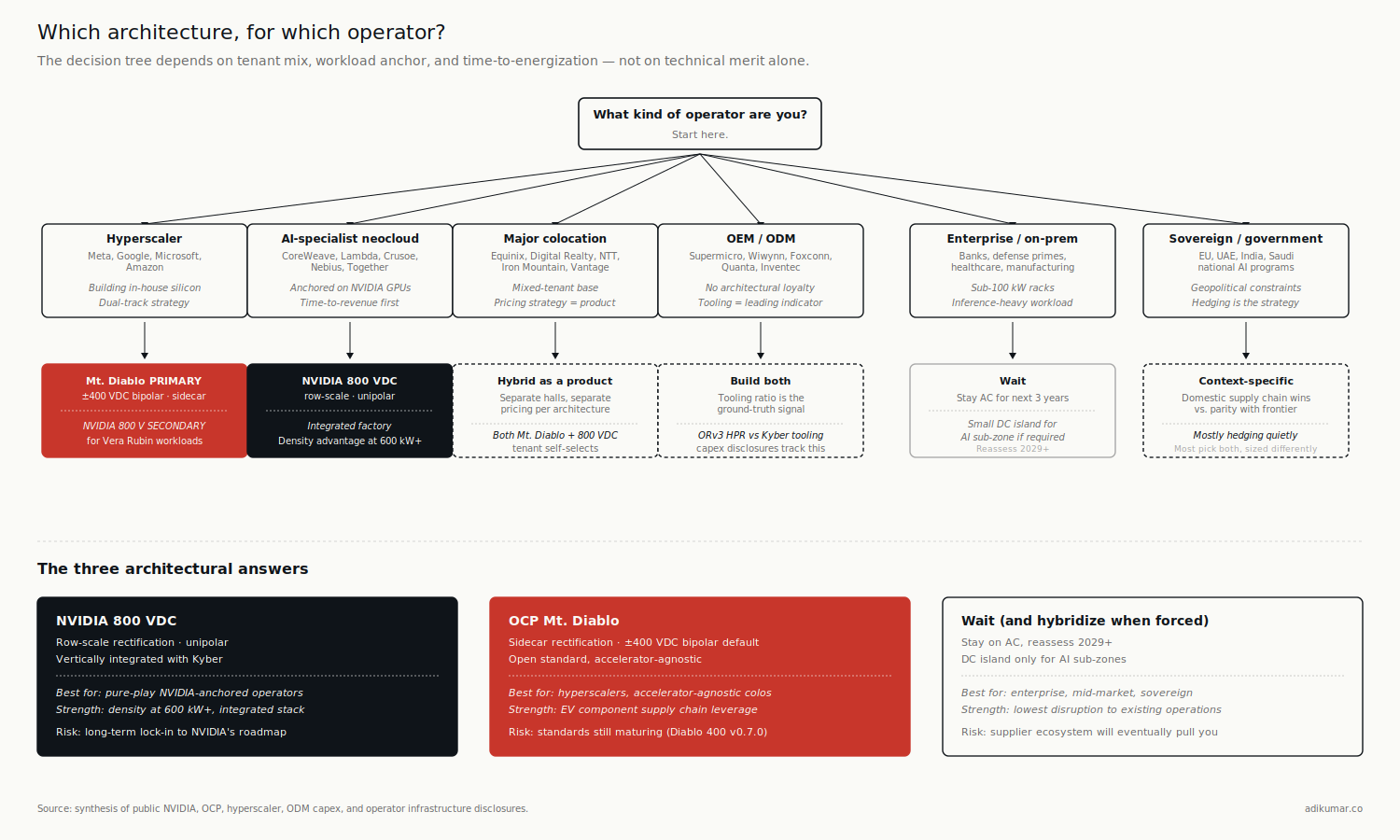
With that in the picture, six operator archetypes — and the architectural answer is different for each.
The hyperscaler running its own silicon (Meta, Google, Microsoft, Amazon). Mt. Diablo, with very high probability, as the primary architecture. They authored the spec, they want the EV supply chain on the bipolar default, and their compute platform is accelerator-agnostic by design. NVIDIA's row-scale 800 VDC architecture is the secondary architecture for this archetype, not the primary one — they will operate it where they host NVIDIA-tenant or Vera Rubin workloads, but their default new-build power architecture is sidecar.
The AI-specialist neocloud (CoreWeave, Lambda, Crusoe, Nebius). Almost certainly NVIDIA 800 VDC. Their entire value proposition is "fastest path to NVIDIA capacity." They don't have the volume to influence Mt. Diablo's roadmap, they don't run alternative silicon, and time-to-revenue dominates everything else. The density advantage of unipolar 800 V matters here too as Vera Rubin Ultra deployment scales.
A note on stranded capex risk for any single-architecture bet. NVIDIA's pattern across the Hopper-to-Blackwell-to-Vera Rubin transitions tells you something about the speed at which rack-level specs change. In three generations the rack jumped from ~50 kW air-cooled, to 140 kW liquid-cooled, to 600 kW liquid-cooled with 800 VDC — each transition stranding prior facility-side investment. CBRE puts the liquid-cooling retrofit cost alone at $2-5M per rack row. If you build an 800 V Kyber row in 2026 and NVIDIA's 2029 generation shifts the voltage class again, or the mechanical interface, or the cooling spec, the building-side capex doesn't transfer cleanly. The chips amortize over 2-3 years; the infrastructure is supposed to amortize over 15-25. That mismatch is a strategic problem for any operator whose architecture choice is locked to a single vendor's roadmap. It's a particular problem for AI-specialist neoclouds because their balance sheet can't absorb the asymmetry. It's a smaller problem for hyperscalers because they have multi-tenant flexibility and silicon optionality. It's why the enterprise "wait" answer below isn't actually conservatism — it's pattern recognition.
The major colocation operator with mixed AI tenants (Equinix, Digital Realty, Vantage, NTT). Hybrid as a product, not a hedge. Different halls for different tenants. Some operators will offer Mt. Diablo halls for hyperscaler tenants, some 800 VDC halls for neocloud tenants, and a lot of legacy AC for the long tail. The commercial sophistication comes from pricing each architecture distinctly, not from picking one.
The OEM / ODM (Supermicro, Wiwynn, Foxconn, Quanta, Inventec). They build both. Watch which lines they're tooling up: the ratio of capex going to ORv3 HPR-compatible chassis versus NVIDIA reference (MGX, Kyber) lines is one of the cleanest leading indicators of which architecture is winning by volume. Today the ratio splits roughly evenly across the major ODMs; the trajectory matters more than the snapshot. The ODMs have no architectural loyalty — they go where the tonnage is.
The enterprise running on-prem AI for regulated workloads (banks, defense primes, healthcare systems). Probably neither, for the next three years. Stay AC, deploy a small DC island for the AI sub-zone, take the inefficiency hit. The skills, the certifications, and the supplier relationships aren't there yet, and the workloads (mostly inference, mostly small training runs) don't justify the architectural commitment.
The sovereign AI operator (national champions in EU, UAE, India, etc.). Depends entirely on supply chain politics. If the priority is geopolitical independence from NVIDIA's ecosystem, Mt. Diablo provides a credible path. If the priority is parity with the US AI frontier, NVIDIA 800 VDC. Most are quietly hedging.
7. What to watch over the next eighteen months
Three signals will tell you which architecture is gaining ground faster.
Component pricing parity. Track the bill of materials for an 800 V SST versus a ±400 V bipolar rectifier of equivalent capacity. Today the 800 V part is roughly 15-25% more expensive at the component level. The gap will close — that's the direction the learning curve points — but the timing depends on annual unit volumes hitting the threshold where 800 V parts move down the experience curve at EV-class rates. Watch component supplier price lists, not analyst forecasts.
ODM tooling ratio. As above — what fraction of new chassis tooling at Supermicro, Wiwynn, Foxconn, Quanta, Inventec is going to ORv3 HPR vs. NVIDIA reference. Quarterly capex disclosures and supplier earnings calls are the source. The ODMs have no loyalty; their tooling decisions are the ground truth.
Standards extensions. UL 98B coverage extending cleanly to 800 V data centre topologies. IEEE 1709 next revision. IEC 61140 DC supplements. If standards bodies write language that explicitly accommodates both unipolar and bipolar, hybrid wins. If they prefer one, that one wins.
Update: Since this essay was published, the picture has moved, and in a direction worth recording. The first-generation divergence it describes NVIDIA's 800 V unipolar reference and OCP Mt. Diablo's ±400 V bipolar default was real, and it traces to a shared starting point: both camps began at the rack, and both selected their voltages to inherit the existing EV supply chain rather than build a new one. Where they initially split was topology, not intent.
The response has been coordination rather than a winner-takes-all standards fight. IT players and electrical OEMs have converged in the OCP 800VDC subcommittee and engaged with with standards bodies, with the explicit goals of underwriting a safe transition, keeping a diversified supplier base behind every "brick" of the stack, and sparing manufacturers the burden of building to radically different specifications. That is a better outcome than the divergence the essay captured at a single point in time, and it is worth saying so. Original essay follows
8. The operator's question
If you're the executive responsible for an AI infrastructure budget in 2026, the question isn't "which architecture should I bet on?"
The question is: given my workload mix, my supplier relationships, and my time-to-revenue requirement, which architecture costs me less to be wrong about?
For most operators, the answer is the architecture your biggest tenant or partner is already committed to. Inertia is rational here. The sophistication is in recognizing that you'll probably be operating both architectures by 2030 — and writing your supplier contracts now to keep that option open.
Essay 2 of 13 in The DC Transition series. Subscribe to get each essay as it publishes.
Sources
- NVIDIA FY2025 data centre revenue ($115.2B): NVIDIA Q4 FY2025 earnings.
- NVIDIA FY2026 data centre revenue (~$194B): Silicon Analysts (April 2026 update) referencing FY2026 trajectory.
- AI accelerator market share trajectory (peak ~95% → 80-86% in 2025-26 → ~75% by end-2026): consensus across Silicon Analysts, TrendForce (October 2025), SemiAnalysis Q4 2025 model, Bloomberg Intelligence (January 2026).
- Custom ASIC CAGR (44.6%): Bloomberg Intelligence "AI Accelerator Chips 2026 Outlook Deep Dive," January 2026.
- ASIC shipments crossing GPU shipments by 2028: Counterpoint Research (cumulative 40M ASIC chips deployed across top 10 hyperscalers, 2024-2028).
- TPU v7 Ironwood 2026 shipment scale (~4.3M units, cumulative tens of millions across 2026-2028): industry market sources covered in The Next Web (April 2026), Jon Peddie Research (December 2025).
- Anthropic Ironwood commitment (>1M chips, >1 GW): Google Cloud / Anthropic joint announcement, late 2025.
- Trainium 3 architecture (144 chips per UltraServer, 32 per rack in NL32x2 SKU, 3nm, GA December 2025): AWS re:Invent 2025; AWS Neuron documentation; SemiAnalysis "AWS Trainium3 Deep Dive," December 2025.
- Project Rainier (Trainium 2, 500K+ chips with Anthropic): AWS, 2025.
- ABB UL 98B 2 kV certification (July 2025, utility-scale solar application, UL 98B native test scope is to 1500 V): ABB press release, July 16 2025; pv-magazine USA, July 17 2025.
- OCP Diablo 400 specification: Diablo 400 Project: Rack and Power v0.7.0 Base Specification, March 2026 (prior versions: v0.5.0 May 2025, v0.5.2 May 2025).
- Sidecar vs row-scale architectural framing: Glenn K. Lockwood, "Mt. Diablo" reference note (May 2025); Diablo 400 v0.7.0 spec text on permitted output configurations.
- Stranded capex risk framing: Hopper-to-Blackwell-to-Vera Rubin rack power trajectory (50 kW → 140 kW → 600 kW) per NVIDIA technical disclosures and IntuitionLabs deep-dive (March 2026); Goldman Sachs AI Infrastructure report (2025) on Blackwell facility-upgrade implications; CBRE Group infrastructure report (2025) on liquid-cooling retrofit costs ($2-5M per rack row).
