
The data centre industry has settled on a comfortable story: AI racks need too much power, and low-voltage AC simply can't carry the current required at scale. The story is true. It is also misleading.
The conversion to high-voltage DC is happening, but treating it as a single phenomenon — driven by power density alone — misses what makes the transition consequential. Four forces are driving this shift, and they operate on different timescales, with different commercial implications. Operators who understand only one of them will design facilities that are technically functional but commercially disadvantaged for the decade ahead.
This essay walks through all four. It is the first in a thirteen-part series on the architecture, economics, and competitive dynamics of the DC transition. Subsequent essays will go deeper into specific stages of the value chain, the architectural debates that will shape the next generation of AI data centres, and the operating-model questions — pricing, partnerships, build-versus-buy — that the technical conversation tends to skip.
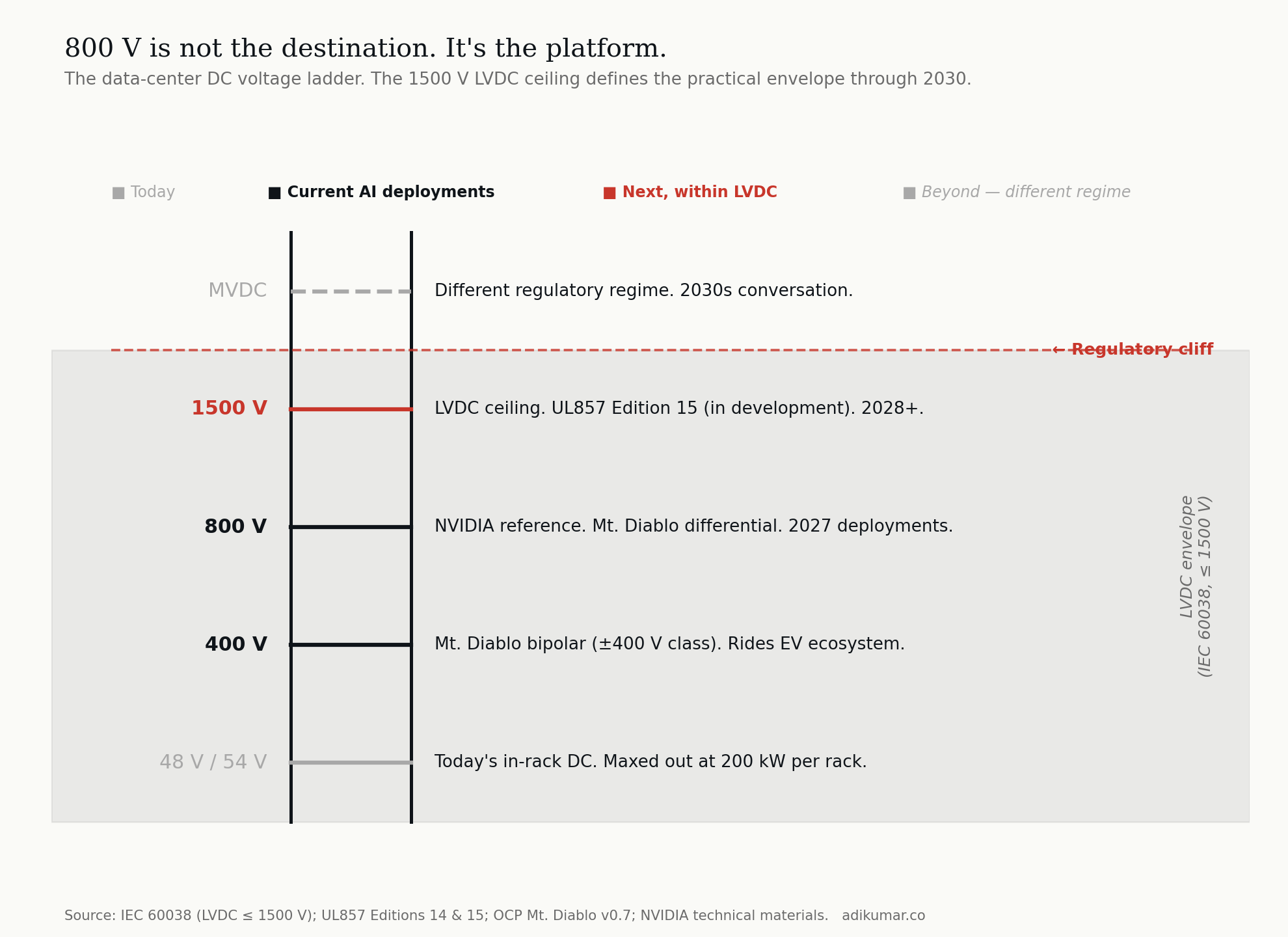
A note on terminology before we start You will see this transition described in trade press as the move to "HVDC" high-voltage DC. That is not technically correct. Under IEC 60038, the international standard that governs voltage classification, high voltage begins at 35 kV. Anything below 1500 V on the DC side is low-voltage DC, or LVDC. The 800 VDC architecture this essay is about , the ±400 V Mt. Diablo specification, and even the 1500 V architectures coming next — all sit firmly inside the LVDC envelope. The trade press calls it HVDC because compared to the 12 V and 48 V conventions data centres have used for decades, 800 V feels high. But the standards body has a different view, and so do the regulatory and certification frameworks that govern equipment design. This is more than pedantry. The boundary between LVDC and MVDC at 1500 V is a genuine regulatory cliff that shapes which equipment classes operators can deploy through 2030 and beyond. We will return to it in section 7. For the rest of this essay and the rest of the series, I will use 800 VDC and LVDC where they are the technically correct terms. DC transition is the framing for the broader shift across the industry.
1. The physics: copper's inconvenient truth
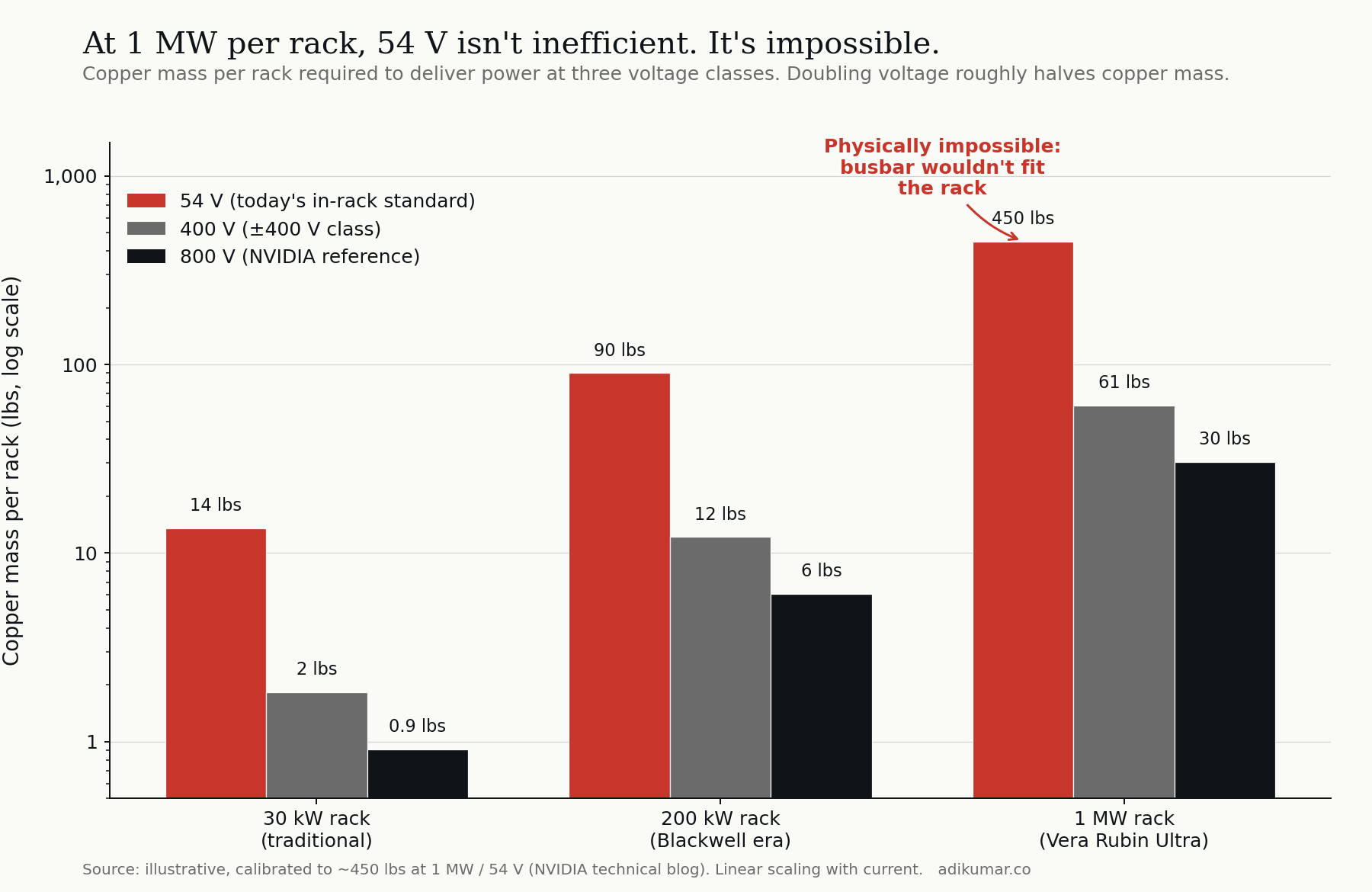
The most straightforward force is the one everyone names. Power equals voltage times current. At fixed power, doubling voltage halves current. Halving current roughly halves the copper required to carry it without overheating.
For traditional racks at 30 kW, this trade-off is academic. For 200 kW racks (Blackwell-class) it becomes interesting. For 1 MW racks (the Vera Rubin Ultra envelope) it becomes binary. At 1 MW per rack and 54 V — today's in-rack standard — the busbar physically does not fit inside the rack. Not "is inefficient." Not "is expensive." Does not fit.
Voltage doubling roughly halves the copper. At 800 V, the same 1 MW delivers through a busbar that's a fraction of the size and weight, and crucially, fits inside the rack envelope.
This is the force every press release names, and it's real. But if it were the whole story, we would simply move from 54 V to whatever voltage carries 1 MW conveniently, declare victory, and go home. The other three forces explain why we're going much further.
2. The conversion chain: stages compound
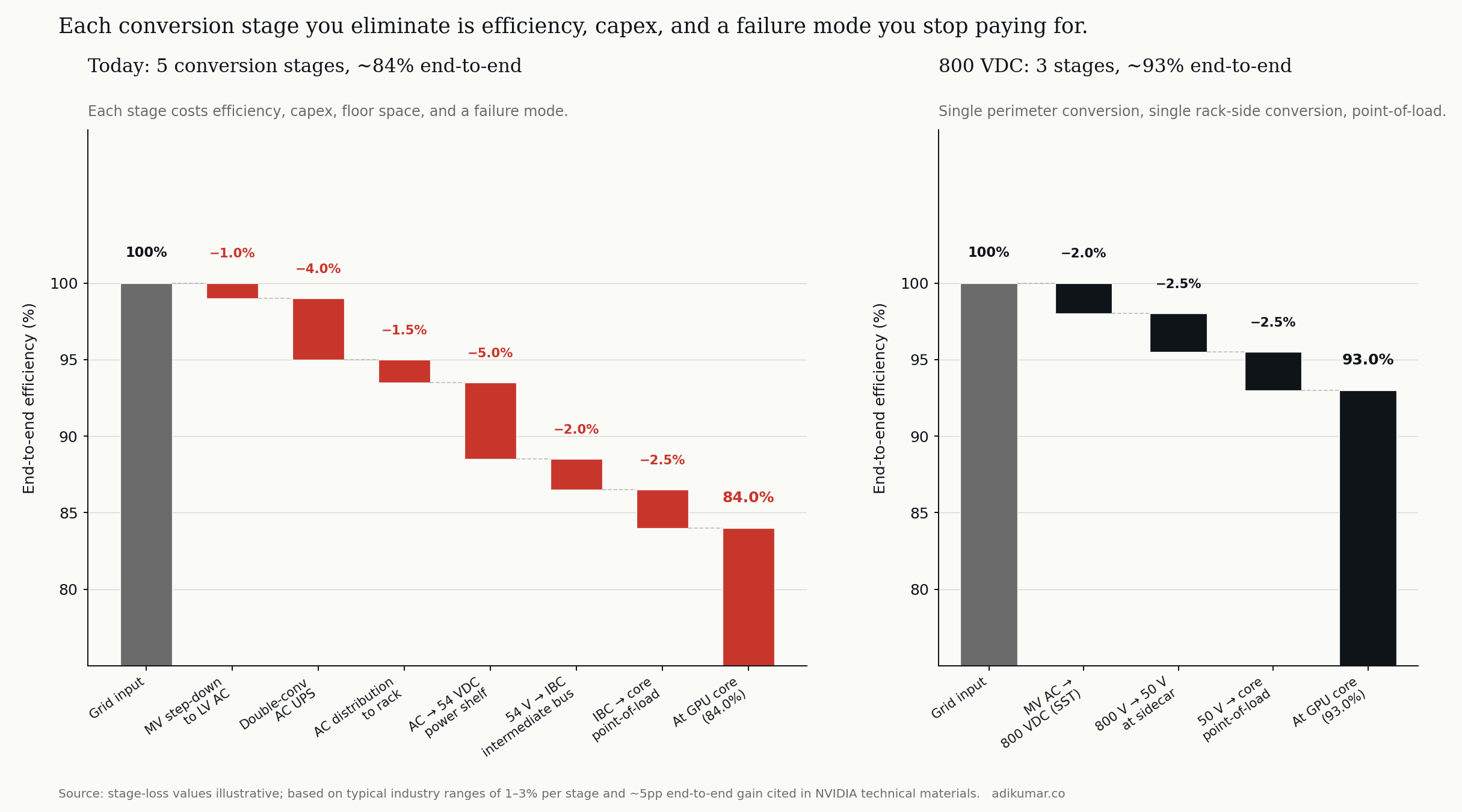
Today's AC architecture for an AI data centre carries through roughly five conversion stages between the grid and the GPU core: medium-voltage AC step-down to low-voltage AC, double-conversion AC UPS for power conditioning and ride-through, AC distribution to the rack, AC-to-DC conversion at the rack-mount power shelf, and a final point-of-load conversion at each accelerator.
Each stage costs efficiency. Best-in-class equipment runs 96–98 percent efficiency per stage; less-than-best equipment runs 93–95 percent. Compound those across five stages and end-to-end efficiency lands somewhere around 84 percent. For a 100 MW facility, the 16 percent loss is 16 MW of waste heat that has to be cooled, plus 16 MW of grid power that has to be procured, paid for, and accounted for in carbon footprint.
The 800 VDC architecture compresses this chain. A single perimeter conversion takes medium-voltage AC to 800 VDC at the building edge. A single rack-side conversion steps to the 50 V class for delivery to the GPU. A point-of-load conversion at the accelerator finishes the job. Three stages, not five. End-to-end efficiency moves from 84 to roughly 93 percent.
The efficiency story is the visible one. The hidden one is failure modes. Each conversion stage is a piece of equipment that can fail, contains capacitors that age, requires service contracts, has firmware that needs updating, occupies floor space that costs money. Eliminating two stages eliminates two equipment categories from the operator's reliability spreadsheet. The capex savings get the headlines; the opex savings — over a 15-year facility life — are larger.
3. The roadmap: the procurement calendar runs ahead
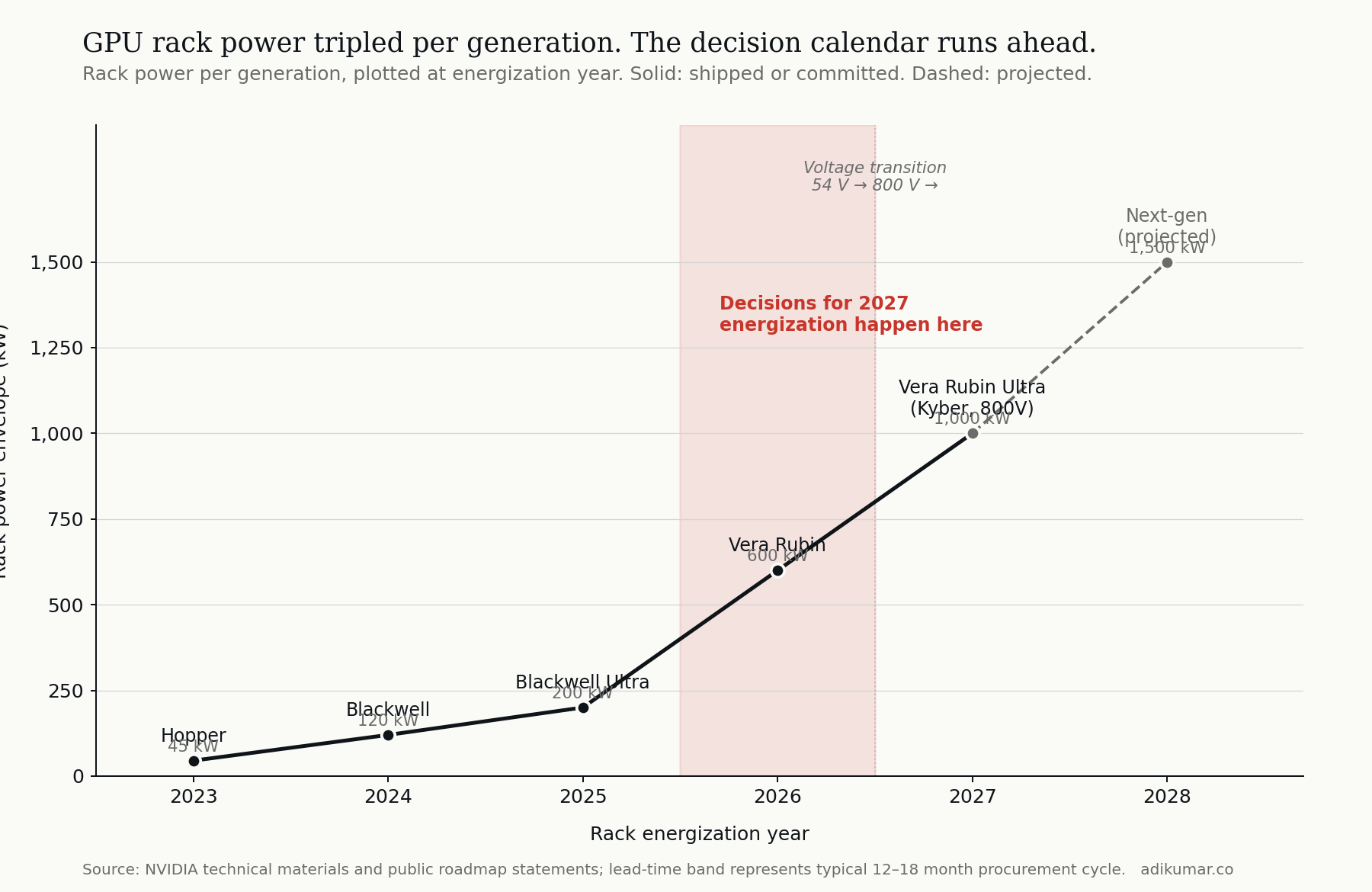
The third force is the one that moves the timetable. NVIDIA's GPU roadmap is public, and it is brutal:
- Hopper-class racks: ~45 kW
- Blackwell-class: ~120 kW
- Blackwell Ultra: ~200 kW
- Vera Rubin: ~600 kW
- Vera Rubin Ultra (Kyber): ~1,000 kW
- Next generation (projected): ~1,500 kW
The thing operators tend to underestimate is that this is not a forecast — it is a backlog. Each generation's procurement decisions are made roughly 12 to 18 months before energization. A facility coming online in 2027 with Vera Rubin Ultra-class racks is not being designed in 2027. It's being designed and committed now, in 2026.
That means the question facing every greenfield AI data centre operator in 2026 is not "should we build for today's power density?" It is: which voltage architecture do we commit to for the silicon we will deploy in 2027 and replace in 2028? Conservatism — building for 100 kW racks because that's what's installed today — is not actually the cautious choice. It is a choice to retrofit, twice, in the next four years.
The procurement calendar has eaten the deliberation timeline. Operators who don't see this end up buying decisions they didn't know they were making.
4. The workload: AI training breaks the assumptions
The fourth force is the most subtle and the one I find most interesting from an operating-model perspective.
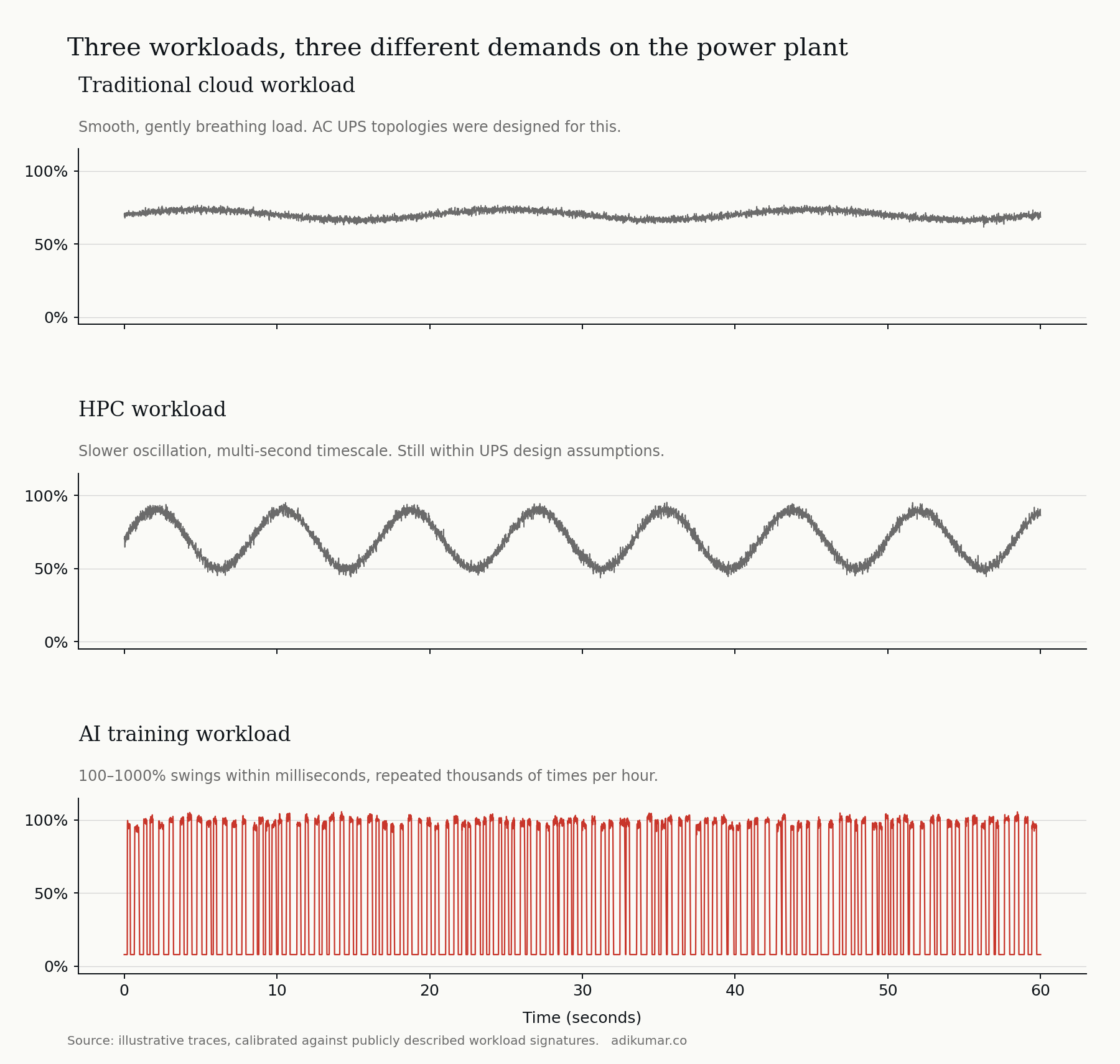
The power-quality assumptions baked into the AC architecture were designed for traditional cloud workloads — relatively steady load, gentle hour-over-hour variation, and demand patterns that follow predictable diurnal cycles. AC UPS topologies, rotary backup systems, and the control logic that governs them assume the load is well-behaved.
AI training workloads are not well-behaved. A large training job synchronizes thousands of GPUs to step in lockstep through forward and backward passes. The aggregate power signature shows step-changes between near-idle and near-peak, repeated thousands of times per hour, with rise and fall times in the tens of milliseconds. From the grid's perspective, an AI training facility looks like a constantly-pulsing load — and a single such facility at hyperscale is now meaningfully visible on the local grid frequency.
Traditional AC UPS architectures handle this poorly. Voltage transients on the grid side, control-loop oscillation, inverter stress, and battery cycling all degrade in the face of high-frequency synchronized swings. Operators are responding with bigger UPS systems, more aggressive grid filtering, and increasingly with on-site battery energy storage (BESS) sized to absorb the worst of the swings before they propagate to the utility connection.
DC architectures handle volatile loads more naturally. The intermediate DC bus acts as a low-impedance reservoir between the grid and the load. Battery storage — the BESS — couples to the DC bus directly, without inverter stages between storage and the demand it's smoothing. The 800 VDC architecture isn't only delivering power more efficiently; it's delivering power that the silicon's volatility doesn't disturb.
This is also why utilities are starting to express opinions. A 500 MW AC-coupled AI factory looks different on the grid than a 500 MW DC-coupled facility with on-site BESS. The grid economics — interconnection, demand charges, ancillary services revenue — are not the same. The architectural choice affects the utility relationship, and through it, the cost of power for the next twenty years.
5. Putting the four forces together
Each force, taken alone, is a reason to consider the transition. Taken together, they describe a structural inflection rather than an incremental upgrade.
- The physics force sets the floor: above ~200 kW per rack, the legacy in-rack voltage cannot continue.
- The conversion-chain force sets the medium-term economics: each stage you eliminate is efficiency, capex, floor space, and a failure mode you stop paying for.
- The roadmap force sets the timing: if you are designing a 2027 facility, the architectural decision has to be made now.
- The workload force sets the operating envelope: AI's volatility makes DC architectures structurally better at coupling to the grid through BESS.
The mistake I see most often, in conversations with operators, is treating this as an "AI infrastructure" question rather than as the largest power-architecture transition the data centre industry has run since the move from rotary UPS to static UPS in the 1990s. It is the latter.
6. A note on what this means for everyone who is not training frontier models
The four forces above describe what's happening at the leading edge: hyperscalers, AI-specialist neoclouds, the Top 10 AI factory builders. For the rest of the data centre industry — the vast colocation base, enterprise on-prem, mid-market — the question is more nuanced.
A 30-rack colocation hall serving general-purpose enterprise workloads at 10–20 kW per rack does not need 800 VDC. It probably never will. A regional colocation operator with mixed tenant types may need to plan for hybrid facilities where part of the floor is built to legacy specifications and part is built to the new envelope. The challenge for these operators is not the technical decision; it is the commercial decision about which tenants you intend to serve in 2030.
The supplier ecosystem reorganizing around DC Transition will eventually pull mid-market operators forward, but the timeline is much longer. Operators in this segment have time. They should be using it to think hard about which side of the eventual market they want to be on, and to make supplier choices with that in mind.
7. The 1500 V ceiling, and what comes next
One question I get often is whether 800 V is the destination or just a waypoint. The honest answer is the latter.
The IEC 60038 standard defines low-voltage DC (LVDC) as DC up to 1500 V. Below this threshold, equipment certification, building codes, and electrical safety regulations operate under one set of rules. Above 1500 V, you cross into medium-voltage DC (MVDC), which has different requirements, different equipment classes, and different regulatory regimes.
The practical envelope for the next five-to-seven years sits between 400 V and 1500 V. Today's reference architectures cluster at 400 V and 800 V because component supply chains support those classes today. The next move — towards 1500 V — is technically straightforward but commercially gated by UL857 Edition 15 (in development), corresponding IEC standards, and the volume ramp of components rated for the higher class. Realistic timeline: 2028 and beyond.
MVDC for data centres is a 2030s conversation, and a different one — different regulatory regime, different equipment, different siting implications. We will get there, but not soon.
8. The four forces, summarized
If you remember nothing else from this essay, remember this:
The DC transition in AI data centres is being driven by four forces, not one. Power density is necessary but not sufficient as an explanation. Conversion-chain economics, the procurement calendar, and AI workload volatility are each independently sufficient reasons to make the move — and together they make the transition not a question of "if" but of "which architecture, on what timeline, with which suppliers."
Operators who understand only the first force will design facilities that are technically functional but commercially disadvantaged. Operators who understand all four will be the ones positioned to capture the next decade of this market.
9. What's next in this series
This essay is the first of thirteen. The next essay — Two Architectures Wearing The Same Name — examines the two reference designs that dominate today's conversation: NVIDIA's centralized 800 VDC and OCP Mt. Diablo's bipolar ±400 VDC. They share a name. They share almost nothing else.
Subsequent essays will go deeper into specific stages of the power chain, the safety implications of DC arc behaviour, the supply-chain dynamics, and the operating-model questions that determine which players capture value as this transition compounds.
If you want to follow along, subscribe to the newsletter to get each essay as it publishes.
